
Python网络爬虫与如何爬取段子的项目实例
2018-06-18 03:32:12来源:未知 阅读 ()

一、网络爬虫
Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。网络爬虫另外一些不常使用的名字还有蚂蚁,自动索引,模拟程序或者蠕虫。爬虫就是自动遍历一个网站的网页,并把内容都下载下来.

搜索引擎与网络爬虫
二、通用性搜索引擎(通用爬虫)
随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎(Search Engine),例如传统的通用搜索引擎AltaVista,Yahoo!和Google等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。但是,这些通用性搜索引擎也存在着一定的局限性,如:
(1) 不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。
(2)通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。
(3)万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。
(4)通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。与通用爬虫(general?purpose web crawler)不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
三、聚焦爬虫实例之爬取段子的爬虫
以糗事百科为例子。
糗事百科是不需要登录的,所以也没必要用到Cookie,另外糗事百科有的段子是附图的,我们把图抓下来图片不便于显示,那么我们就尝试过滤掉有图的段子吧。
好,现在我们尝试抓取一下糗事百科的热门段子吧,每按下一次回车我们显示一个段子。
1.确定URL并抓取页面代码
首先我们确定好页面的URL是 http://www.qiushibaike.com/hot/page/1,其中最后一个数字1代表页数,我们可以传入不同的值来获得某一页的段子内容。
我们初步构建如下的代码来打印页面代码内容试试看,先构造最基本的页面抓取方式,看看会不会成功
\# -*- coding:utf-8 -*-
import urllib
import urllib2
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
try:
request = urllib2.Request(url)
response = urllib2.urlopen(request)
print response.read()
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
运行程序,哦不,它竟然报错了,真是时运不济,命途多舛啊
line 373, in _read_status raise BadStatusLine(line) httplib.BadStatusLine: ''
好吧,应该是headers验证的问题,我们加上一个headers验证试试看吧,将代码修改如下
\# -*- coding:utf-8 -*-
import urllib
import urllib2
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
try:
request = urllib2.Request(url,headers = headers)
response = urllib2.urlopen(request)
print response.read()
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
嘿嘿,这次运行终于正常了,打印出了第一页的HTML代码,大家可以运行下代码试试看。在这里运行结果太长就不贴了。
2.提取某一页的所有段子
好,获取了HTML代码之后,我们开始分析怎样获取某一页的所有段子。
首先我们审查元素看一下,按浏览器的F12,截图如下
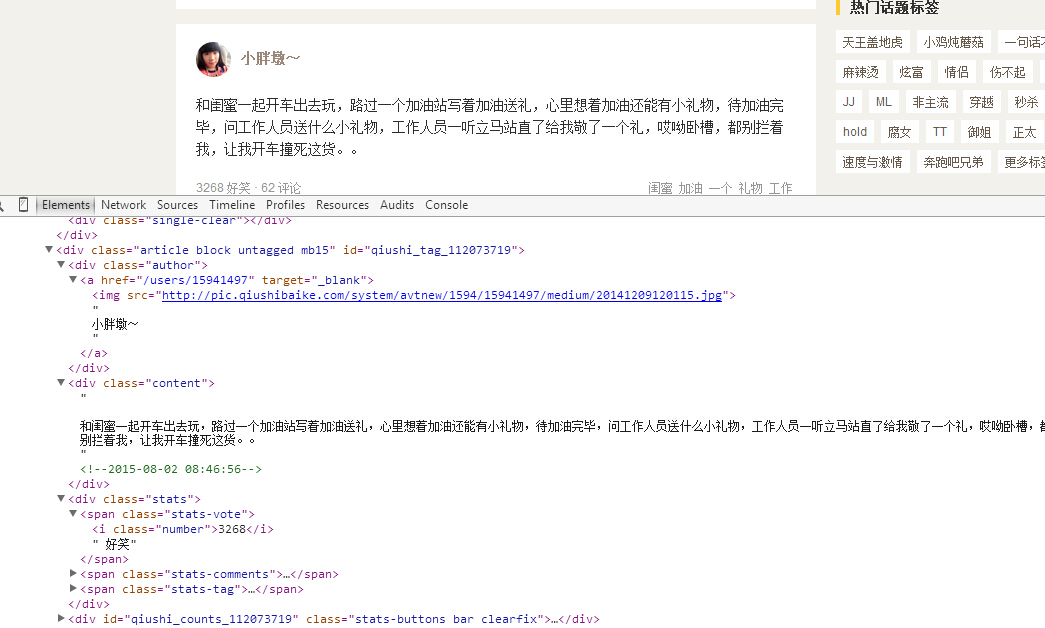
我们可以看到,每一个段子都是
content = response.read().decode('utf-8')
pattern = re.compile('<div.*?author">.*?<a.*?<img.*?>(.*?)</a>.*?<div.*?'+
'content">(.*?)<!--(.*?)-->.*?</div>(.*?)<div class="stats.*?class="number">(.*?)</i>',re.S)
items = re.findall(pattern,content)
for item in items:
print item[0],item[1],item[2],item[3],item[4]
现在正则表达式在这里稍作说明
1. ? 是一个固定的搭配,.和代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配,以后我们还会大量用到 .*? 的搭配。
2. (.?)代表一个分组,在这个正则表达式中我们匹配了五个分组,在后面的遍历item中,item[0]就代表第一个(.?)所指代的内容,item[1]就代表第二个(.*?)所指代的内容,以此类推。
3. re.S 标志代表在匹配时为点任意匹配模式,点 . 也可以代表换行符。
这样我们就获取了发布人,发布时间,发布内容,附加图片以及点赞数。
在这里注意一下,我们要获取的内容如果是带有图片,直接输出出来比较繁琐,所以这里我们只获取不带图片的段子就好了。
所以,在这里我们就需要对带图片的段子进行过滤。
我们可以发现,带有图片的段子会带有类似下面的代码,而不带图片的则没有,所以,我们的正则表达式的item[3]就是获取了下面的内容,如果不带图片,item[3]获取的内容便是空。
<div class="thumb"> <a href="/article/112061287?list=hot&s=4794990" target="_blank"> <img src="/info/upimg/allimg/180618/0332222044-1.jpg" alt="但他们依然乐观"> </a> </div>
所以我们只需要判断item[3]中是否含有img标签就可以了。
好,我们再把上述代码中的for循环改为下面的样子
for item in items:
haveImg = re.search("img",item[3])
if not haveImg:
print item[0],item[1],item[2],item[4]
现在,整体的代码如下
\# -*- coding:utf-8 -*-
import urllib
import urllib2
import re
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
try:
request = urllib2.Request(url,headers = headers)
response = urllib2.urlopen(request)
content = response.read().decode('utf-8')
pattern = re.compile('<div.*?author">.*?<a.*?<img.*?>(.*?)</a>.*?<div.*?'+
'content">(.*?)<!--(.*?)-->.*?</div>(.*?)<div class="stats.*?class="number">(.*?)</i>',re.S)
items = re.findall(pattern,content)
for item in items:
haveImg = re.search("img",item[3])
if not haveImg:
print item[0],item[1],item[2],item[4]
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reaso
运行一下看下效果:
这之中省去1千字。。。。。。
不要喷我,我给你们准备了最好的礼物:
尚学堂Python爬虫实战项目-如何爬取段子的视频教程。
大家可以找可爱又美丽的Teacher 唐 获取下载地址吧!
她的扣扣是2056217415 ,,17301781330
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- python3基础之“术语表(2)” 2019-08-13
- python3 之 字符串编码小结(Unicode、utf-8、gbk、gb2312等 2019-08-13
- Python3安装impala 2019-08-13
- 小白如何入门 Python 爬虫? 2019-08-13
- python_字符串方法 2019-08-13
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
