
Python3 ����ʵս��������ȡ��
2018-06-18 03:00:25��Դ��δ֪ �Ķ� ()

1 ����
����һϵ�п�ʼǰ���Ǿ�˵��������������ף�����Ҫ���һ����Ч��׳�����治��һ�������飬��һϵ�������Ѿ�������������ص����º���֪ʶ�㡣

���������⼸ƪ��ʵ���ǰ����浱���Լ������Ŀ���������ʹ�û������ǹ��ˣ�Ʃ���ϰ����㶨������۲��Լ�����Ӧ�ù������ߺ���û���Ϊ���ݣ����㿪�����չ���DZ�ڷ��գ������ʵ���ǾͿ���д�� Python ����С����ȥ��̨���ڲ飬Ȼ�����ʼ����͵��ҵ����䣬�����Ͳ����Լ��ϼ��������Ȼ��ȥ����ҳ�����ˣ������Ƕ��ڶ�̬��ҳ��ȡ���ǻ�δ̽�֡�������ȡ���ݴ�������Ҳû̽�֡�������ȡ������������Ҳû̽�֡������ҿ������кܶණ���ȴ�����ȥ����MLGB����������һƪ����̽���� Python ����IJ�����ȡ����ʵ���� Python �IJ��������أ�
֮�����������������Ϊ�˽����Python3.X ����ʵս����̬�����������������һ���� LXml ������ȡ��ͼ¼��ŮͼƬ��վ��Ч�����⣬��ᷢ��������һƪ���Ǹ������ִ��Ч�ʷdz��ͣ���ȡ����Щ����ͼ��Ҫ�ܾͣ���Ϊ������˳��ģ��������ǻ�û�ж�����ͼ��վ����ȫվ��ȡ�����Ҫȫվ��ȡ�Ǿ��Ǹ��൱�ֲ��������ˣ��������ǿ���ͨ����Python3.X ����ʵս�����������ˣ���һ�Ľ��ܵ� site ��ʽ�鿴���վ���ж���ҳ�������ȡ�����£�

������ر�࣬�������Ѿ���������ô������ȡ�ٶ��ˣ��������Ǿ�Ҫ��취���������⣬Ҳ������һƪҪ̽�ֵ����⣬����������þ߱� Python ������̵Ļ������������ OK ���Կ���֪���� Python ֮���� Python �������ϵ�����£����IJ���������ȥ���� Python ���ı��һ�顣
2 Python 3.X �����̵�
��ʵ��һС��û��Ҫ���ڵģ�����Ϊ�˲�ȫ���г����ˣ�ע�⣺����Լ��߱�����������ֱ���Ʋ� Part3 ��������ʵս�������ڳ���Ľ��̡��̹߳�ϵ������ĸ�����ʵ�Dz����־��������Եģ�Ҳ��˵������ǹ�ȥ�ڼ����������Unix �� C ���Ա�̡�Java ��̡�Android ��̵�ѧϰ���������̵߳ĸ����ô Python �IJ���Ҳ�ͺ������ˣ�Ψһ���������ǵ���� API ���ּ��÷���ͬ���ѡ�
Python3 ʹ�� POSIX ���ݵģ�pthreads���̣߳��ṩ�˶�����̱߳��ģ�飬Ʃ�� _thread��threading��Queue��concurrent.futures ���ȣ����� _thread��threading �������Ǵ��������̣߳���Ҫ������� _thread ����ǰ Python �е� thread��Python3 ���Ѿ�������ʹ�� thread ģ�飬Ϊ�˼��� Python3 ����������Ϊ _thread �ˣ�ֻ�ṩ�˻������̼߳���֧�֣��� threading �ṩ�˸���ţ�Ƶ��̹߳������ƣ�Queue Ϊ�����ṩ��һ�����ڶ��̹߳������ݵĶ��У�concurrent.futures���� Python3.2 ��ʼ�������˱��⣬���ṩ��ThreadPoolExecutor �� ProcessPoolExecutor �Ƕ� threading �� multiprocessing �ĸ�����¶ͳһ�Ľӿ�������ʵ���첽���á�
2-1 Python 3.X _thread ģ��
���Ǹ����ܴ�������� Python ����ģ�飬�� Python �Ͱ汾�н� thread���߰汾Ϊ�˼��ݽ� _thread�����Dz��Ƽ�ʹ���ˣ����岻�Ƽ���ԭ��������£�
- _thread ģ���ͬ��ԭ��ֻ��һ�����Ƚ�����threading ȴ�кܶࣻ
- _thread ģ��֮������˸��Ӹ��� threading����˵��ѡ�ĸ��أ�
- ��֧���ػ��̵߳ȣ�ʹ�� _thread ģ����ڽ��̸ú�ʱ�������������ƣ����߳̽����������̱߳�û���κξ���������������ǿ�ƽ��������� threading ģ��������Ա�֤��Ҫ���߳̽�������˳����̣߳�
˵��������Ϊ���Ǹ���������Ԧ���� _thread ģ�飬�������������ܵ�ѡ���� threading ģ�飻��˵���ã�ֱ�Ӹ��δ�����ʾ�°ɣ���δ����ڸ������ԵĶ��߳��ж��Ǿ��䣬ûɶ����ģ����£�
1 import _thread 2 import time 3 ''' 4 #Pythonѧϰ����Ⱥ125240963ÿ�����������Ƶ����ţ��� 5 Python 3.X _thread ģ����ʾ Demo 6 ��ע�͵� self.lock.acquire() �� self.lock.release() �����д���ᷢ������ count Ϊ 467195 �����ֵ���������⡣ 7 ������ self.lock.acquire() �� self.lock.release() �����д���ᷢ������ count Ϊ 1000000�������Ʊ�֤�˲����� 8 time.sleep(5) ����Ϊ�˽�� _thread ģ���ڸ����ע�͵��Ļ����߳�û����ִ���� 9 ''' 10 class ThreadTest(object): 11 def __init__(self): 12 self.count = 0 13 self.lock = None 14 15 def runnable(self): 16 self.lock.acquire() 17 print('thread ident is '+str(_thread.get_ident())+', lock acquired!') 18 for i in range(0, 100000): 19 self.count += 1 20 print('thread ident is ' + str(_thread.get_ident()) + ', pre lock release!') 21 self.lock.release() 22 23 def test(self): 24 self.lock = _thread.allocate_lock() 25 for i in range(0, 10): 26 _thread.start_new_thread(self.runnable, ()) 27 28 if __name__ == '__main__': 29 test = ThreadTest() 30 test.test() 31 print('thread is running...') 32 time.sleep(5) 33 print('test finish, count is:' + str(test.count))
���Ժ�ֱ�۵Ŀ�������ȷʵֵ�����������ǻ��ǿ��� threading �ɡ�
2-2 Python 3.X threading ģ��
���� threading ģ���ṩ�Ķ�����ʵ���ǿ���ֱ�ӿ��� threading.py Դ���__all__���壬�����о����о٣����£�
1 __all__ = ['get_ident', 'active_count', 'Condition', 'current_thread', 2 'enumerate', 'main_thread', 'TIMEOUT_MAX', 3 'Event', 'Lock', 'RLock', 'Semaphore', 'BoundedSemaphore', 'Thread', 4 'Barrier', 'BrokenBarrierError', 'Timer', 'ThreadError', 5 'setprofile', 'settrace', 'local', 'stack_size']
�������������� API ��˳���ѵ���ƪ���²��������Ҳ鿴��������Ȥ�Ŀ����Լ�ȥ��ĥ�¿������������ȸ��� threading ģ���� Thread ���һ���÷������£�
1 import threading 2 from threading import Thread 3 import time 4 ''' 5 Python 3.X threading ģ����ʾ Demo 6 #Pythonѧϰ����Ⱥ125240963ÿ��������ϴ�ţָ�� 7 8 threading �� Thread �����ʹ�÷�ʽ���̳���д run ������ֱ�Ӵ��ݷ����� 9 ''' 10 class NormalThread(Thread): 11 ''' 12 ��д��� Java �� Runnable �� run ������ʽ 13 ''' 14 def __init__(self, name=None): 15 Thread.__init__(self, name=name) 16 self.counter = 0 17 18 def run(self): 19 print(self.getName() + ' thread is start!') 20 self.do_customer_things() 21 print(self.getName() + ' thread is end!') 22 23 def do_customer_things(self): 24 while self.counter < 10: 25 time.sleep(1) 26 print('do customer things counter is:'+str(self.counter)) 27 self.counter += 1 28 29 30 def loop_runner(max_counter=5): 31 ''' 32 ֱ�ӱ� Thread ���÷�ʽ 33 ''' 34 print(threading.current_thread().getName() + " thread is start!") 35 cur_counter = 0 36 while cur_counter < max_counter: 37 time.sleep(1) 38 print('loop runner current counter is:' + str(cur_counter)) 39 cur_counter += 1 40 print(threading.current_thread().getName() + " thread is end!") 41 42 43 if __name__ == '__main__': 44 print(threading.current_thread().getName() + " thread is start!") 45 46 normal_thread = NormalThread("Normal Thread") 47 normal_thread.start() 48 49 loop_thread = Thread(target=loop_runner, args=(10,), name='LOOP THREAD') 50 loop_thread.start() 51 52 loop_thread.join() 53 normal_thread.join() 54 55 print(threading.current_thread().getName() + " thread is end!")
��ô������ֱ�ӵĸд�������Ҳ������ _thread ���������߳�Ԥ������ʱ��ȴ����߳̽�����ʹ�� Thread ���Ժ�ֱ�ӿ���ʹ�� join ��ʽ�ȴ����߳̽�������Ȼ���б�ķ�ʽ���Լ�������ĥ�����ǻᷢ��������д���� Java �̷߳dz����ƣ��ܰ������������ٸ�����ͬ�����������������£�
''' Python 3.X threading ģ����ʾ Demo threading ��ͬ������ ��ע�͵� self.lock.acquire() �� self.lock.release() �����д���ᷢ������ count Ϊ 467195 �ȣ��������⡣ ������ self.lock.acquire() �� self.lock.release() �����д���ᷢ������ count Ϊ 1000000�������Ʊ�֤�˲����� ''' import threading from threading import Thread class LockThread(Thread): count = 0 def __init__(self, name=None, lock=None): Thread.__init__(self, name=name) self.lock = lock def run(self): self.lock.acquire() print('thread is '+threading.current_thread().getName()+', lock acquired!') for i in range(0, 100000): LockThread.count += 1 print('thread is '+threading.current_thread().getName()+', pre lock release!') self.lock.release() if __name__ == '__main__': threads = list() lock = threading.Lock() for i in range(0, 10): thread = LockThread(name=str(i), lock=lock) thread.start() threads.append(thread) for thread in threads: thread.join() print('Main Thread finish, LockThread.count is:'+str(LockThread.count))
����һ��IJ���ͬ��ʹ�� Lock ���㹻�ˣ��ɣ����������������ƣ�����__all__ �Ķ��壩�Լ����Բο��������Ͻ���ѧϰ������㵽Ϊֹ�����������������������г��õ��߳����ȼ����У����£� 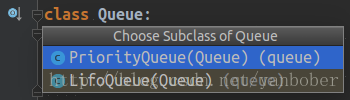
Python3 �� Queue ģ���ṩ��ͬ�����̰߳�ȫ�����࣬���������ȳ����� Queue�������ȳ����� LifoQueue �����ȼ����� PriorityQueue����Щ���ж�ʵ���������ƣ������ڶ��߳���ֱ��ʹ�ã�Ҳ��������Щ������ʵ���̼߳��ͬ�����������һ�����Ǿ����ʾ�����������������⣩�����£�
1 from queue import Queue 2 from random import randint 3 from threading import Thread 4 from time import sleep 5 ''' 6 Python 3.X threading �� Queue �����ʾ Demo 7 ����IJ�������������ģ�� 8 ''' 9 10 class TestQueue(object): 11 def __init__(self): 12 self.queue = Queue(2) 13 14 def writer(self): 15 print('Producter start write to queue.') 16 self.queue.put('key', block=1) 17 print('Producter write to queue end. size is:'+str(self.queue.qsize())) 18 19 def reader(self): 20 value = self.queue.get(block=1) 21 print('Consumer read from queue end. size is:'+str(self.queue.qsize())) 22 23 def producter(self): 24 for i in range(5): 25 self.writer() 26 sleep(randint(0, 3)) 27 28 def consumer(self): 29 for i in range(5): 30 self.reader() 31 sleep(randint(2, 4)) 32 33 def go(self): 34 print('TestQueue Start!') 35 threads = [] 36 functions = [self.consumer, self.producter] 37 for func in functions: 38 thread = Thread(target=func, name=func.__name__) 39 thread.start() 40 threads.append(thread) 41 for thread in threads: 42 thread.join() 43 print('TestQueue Done!') 44 45 if __name__ == '__main__': 46 TestQueue().go()
���Կ�����һ����������س����ͳ��õ� Python3 �߳���ض�����Ҫ��������Щ����Ȼ����һЩ�߶˵��÷��߶˵��߳�������û���ᵽ����Щ��Ҫ�����Լ�ȥ���ۺ������Լ���������ѡ����ʵ��̸߳����ࣻ��������ƪ��������չ������Ϊ�����κ������ú��̲߳�����������һ���dz�����ȵķ����漰������Ҳ�ܶ࣬���Ƕ���һ��ҵ����˵��������ӡ�
2-3 Python 3.X ����ģ��
�������ǽ����� Python3 �� thread ������ػ��������Ƕ�֪���������̻߳��ж���̣����ڴ�ռ仮�ֵȻ��ƶ��Dz�һ���ģ������ڱ���������Ƕ�֪���ġ�Ȼ���� Python �������������ʹ�ö�� CPU ��Դ���Ǿ͵�ʹ�ö���̣�Python �������ṩ�˷dz����õĶ����ģ��� multiprocessing����֧���ӽ��̡�ͨ�ź������ݵȹ��߲������dz�����
������������ multiprocessing �� Process һ���÷���·�ɣ���ʵ��ȫ���� threading �÷���ֻ���������ʵ�ʲ�ͬ���ѣ������£�
1 import multiprocessing 2 import time 3 from multiprocessing import Process 4 ''' 5 Python 3.X multiprocess ģ����ʾ Demo 6 ��ʵ��ȫ���� threading �÷���ֻ���������ʵ�ʲ�ͬ���� 7 multiprocess �� Process �����ʹ�÷�ʽ���̳���д run ������ֱ�Ӵ��ݷ����� 8 ''' 9 class NormalProcess(Process): 10 def __init__(self, name=None): 11 Process.__init__(self, name=name) 12 self.counter = 0 13 14 def run(self): 15 print(self.name + ' process is start!') 16 self.do_customer_things() 17 print(self.name + ' process is end!') 18 19 def do_customer_things(self): 20 while self.counter < 10: 21 time.sleep(1) 22 print('do customer things counter is:'+str(self.counter)) 23 self.counter += 1 24 25 26 def loop_runner(max_counter=5): 27 print(multiprocessing.current_process().name + " process is start!") 28 cur_counter = 0 29 while cur_counter < max_counter: 30 time.sleep(1) 31 print('loop runner current counter is:' + str(cur_counter)) 32 cur_counter += 1 33 print(multiprocessing.current_process().name + " process is end!") 34 35 36 if __name__ == '__main__': 37 print(multiprocessing.current_process().name + " process is start!") 38 print("cpu count:"+str(multiprocessing.cpu_count())+", active chiled count:"+str(len(multiprocessing.active_children()))) 39 normal_process = NormalProcess("NORMAL PROCESS") 40 normal_process.start() 41 42 loop_process = Process(target=loop_runner, args=(10,), name='LOOP PROCESS') 43 loop_process.start() 44 45 print("cpu count:" + str(multiprocessing.cpu_count()) + ", active chiled count:" + str(len(multiprocessing.active_children()))) 46 normal_process.join() 47 loop_process.join() 48 print(multiprocessing.current_process().name + " process is end!")
��ô�������������� Process ʹ�÷�ʽ��������� Thread��ֻ�Ǻ����ԭ�����ڴ���������������������������һ������������ Process �IJ������Ͷ�������ݹ�������ʹ�ã��� Thread ���ڴ������κ�����ͨ�ã������£�
1 ''' 2 Python 3.X multiprocess ģ����ʾ Demo 3 4 multiprocess ��ͬ�����Ƽ��������ݹ������� 5 ��ע�͵� self.lock.acquire() �� self.lock.release() �����д���ᷢ������ count Ϊ 467195 �ȣ��������⡣ 6 ������ self.lock.acquire() �� self.lock.release() �����д���ᷢ������ count Ϊ 1000000�������Ʊ�֤�˲����� 7 ''' 8 import multiprocessing 9 from multiprocessing import Process 10 11 class LockProcess(Process): 12 def __init__(self, name=None, lock=None, m_count=None): 13 Process.__init__(self, name=name) 14 self.lock = lock 15 self.m_count = m_count 16 17 def run(self): 18 self.lock.acquire() 19 print('process is '+multiprocessing.current_process().name+', lock acquired!') 20 #�������⣬100000��ѭ�������������Ż�Ϊ�ȴӶ���̹����ó����������ٷŻض���̹��� 21 count = self.m_count.value; 22 for i in range(0, 100000): 23 count += 1 24 self.m_count.value = count 25 print('process is '+multiprocessing.current_process().name+', pre lock release!') 26 self.lock.release() 27 28 29 if __name__ == '__main__': 30 processes = list() 31 lock = multiprocessing.Lock() 32 m_count = multiprocessing.Manager().Value('count', 0) 33 34 for i in range(0, 10): 35 process = LockProcess(name=str(i), lock=lock, m_count=m_count) 36 process.start() 37 processes.append(process) 38 39 for process in processes: 40 process.join() 41 print('Main Process finish, LockProcess.count is:' + str(m_count.value))
��ѽѽ������һ�ѣ��ܲ����Լ������� threading ������һ����·��Ψһ��������Ϊ�̺߳ͽ��̱��������µģ���ʹ�÷�ʽȴû�������� multiprocessing �� Queue ���� threading �ģ����پ����ˣ������Լ�ʵս�ɡ�
2-4 Python 3.X ������
�� Python �����̵߳���������һ��һ���ߵ�����ᷢ�� Python ����������ṩ�� _thread��threading �� multiprocessing ģ���Ƿdz����ģ���������û�����������������Ҳ��������Ʃ�� C\Java �ȣ���ʵ����Ŀ�д��ģ��Ƶ�������������̻߳��߽�����һ���dz�������Դ�����飬���Գصĸ������ô�����ˣ��ռ任ʱ�䣩������ Python3.2 ��ʼ���ñ���Ϊ�����ṩ�� concurrent.futures ģ�飬ģ������� ThreadPoolExecutor �� ProcessPoolExecutor �����ࣨ������� Executor �����࣬����ֱ��ʹ�ã���ʵ���˶� threading �� multiprocessing �ĸ����Ա�д�̳߳ء����̳��ṩ��ֱ�ӵ�֧�֣�����ֻ�ý���Ӧ�� tasks �����̳߳ء����̳��������Զ����ȶ������Լ�ȥά�� Queue �������������⡣
���������̳߳�������
''' Python 3.X ThreadPoolExecutor ģ����ʾ Demo ''' import concurrent from concurrent.futures import ThreadPoolExecutor from urllib import request class TestThreadPoolExecutor(object): def __init__(self): self.urls = [ 'https://www.baidu.com/', 'http://blog.jobbole.com/', 'http://www.csdn.net/', 'https://juejin.im/', 'https://www.zhihu.com/' ] def get_web_content(self, url=None): print('start get web content from: '+url) try: headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64)"} req = request.Request(url, headers=headers) return request.urlopen(req).read().decode("utf-8") except BaseException as e: print(str(e)) return None print('get web content end from: ' + str(url)) def runner(self): thread_pool = ThreadPoolExecutor(max_workers=2, thread_name_prefix='DEMO') futures = dict() for url in self.urls: future = thread_pool.submit(self.get_web_content, url) futures[future] = url for future in concurrent.futures.as_completed(futures): url = futures[future] try: data = future.result() except Exception as e: print('Run thread url ('+url+') error. '+str(e)) else: print(url+'Request data ok. size='+str(len(data))) print('Finished!') if __name__ == '__main__': TestThreadPoolExecutor().runner()
�����������̳�ʵ�������£�
1 ''' 2 Python 3.X ProcessPoolExecutor ģ����ʾ Demo 3 ''' 4 import concurrent 5 from concurrent.futures import ProcessPoolExecutor 6 from urllib import request 7 8 class TestProcessPoolExecutor(object): 9 def __init__(self): 10 self.urls = [ 11 'https://www.baidu.com/', 12 'http://blog.jobbole.com/', 13 'http://www.csdn.net/', 14 'https://juejin.im/', 15 'https://www.zhihu.com/' 16 ] 17 18 def get_web_content(self, url=None): 19 print('start get web content from: '+url) 20 try: 21 headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64)"} 22 req = request.Request(url, headers=headers) 23 return request.urlopen(req).read().decode("utf-8") 24 except BaseException as e: 25 print(str(e)) 26 return None 27 print('get web content end from: ' + str(url)) 28 29 def runner(self): 30 process_pool = ProcessPoolExecutor(max_workers=4) 31 futures = dict() 32 for url in self.urls: 33 future = process_pool.submit(self.get_web_content, url) 34 futures[future] = url 35 36 for future in concurrent.futures.as_completed(futures): 37 url = futures[future] 38 try: 39 data = future.result() 40 except Exception as e: 41 print('Run process url ('+url+') error. '+str(e)) 42 else: 43 print(url+'Request data ok. size='+str(len(data))) 44 print('Finished!') 45 46 if __name__ == '__main__': 47 TestProcessPoolExecutor().runner()
�����κα�����Զ��ǻ�ͨ�ģ��������������ֻҪ��������һ�����ԣ������Ķ������ף�Ҫ��Ӧ��ֻ��������� Python 3 �IJ�����ʵ���кܶ�֪ʶ����Ҫ����̽���ģ�Ʃ���첽 IO�������������ȵȣ�����Ҫ�����Լ�������ȥѡ��ʹ�ú��ʵIJ���������ֻ��������������ʵģ���֮ѧϰ������һ����·���Cʵս�۲�˼����
3 ��������ʵս
�ű��˰ɣ��������� BB ����ô����� Python �����Ķ�������Ȼ�ܶ�û BB �����Ͼ�����ר�Ž��� Python 3 �����ģ�����Ϊ����ô����� Part ��ʵս�������ӣ���Ȼ��ɶ�����أ��ϻ�����˵�ˣ�����֮ǰд�����涼�ǵ������̵߳ģ������и���Ҫ�����������һ��һ��������ȡ��ס�����ˣ����������ֻ�ܸɵ����ˣ�����һ����������ҵĵ�����ôţ��Ϊë�ҵ����滹�Ǵ�����ȡ��ô����������������ʵ��Ƭ�ξ��������ս�������ڸ���ġ�
3-1 ���߳�����ʵս
ɶ������Ϸ�˵���������Ǹɣ��������Ӵ��룬���ٸ������ö��߳���ʾ�ˣ�ֱ�����̳߳أ����治����ͣ����忴���´����ע�ͻ����Լ���һ�¾������ˡ�
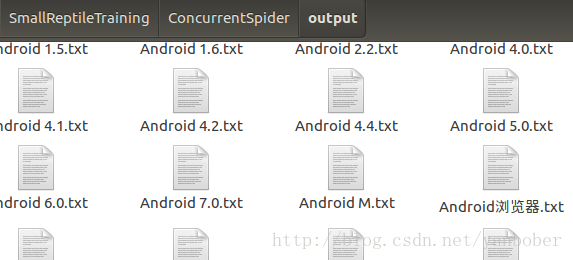
1 import os 2 from concurrent.futures import ThreadPoolExecutor 3 from urllib import request 4 import re 5 from urllib.parse import urljoin 6 from bs4 import BeautifulSoup 7 ''' 8 ʹ�õ��������̳߳���ȡ���������������̳߳ش洢�������ʾ�� 9 ��ȡ�ٶȰٿ�Android������鼰�ô������Ӵ����ļ����Ϣ��������������ǰĿ¼��outputĿ¼ 10 ''' 11 12 class CrawlThreadPool(object): 13 ''' 14 ��������߳���Ϊ5���̳߳ؽ���URL������ȡ����������� 15 ����ͨ��crawl������complete_callback����������ȡ��������ص� 16 ''' 17 def __init__(self): 18 self.thread_pool = ThreadPoolExecutor(max_workers=5) 19 20 def _request_parse_runnable(self, url): 21 print('start get web content from: ' + url) 22 try: 23 headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64)"} 24 req = request.Request(url, headers=headers) 25 content = request.urlopen(req).read().decode("utf-8") 26 soup = BeautifulSoup(content, "html.parser", from_encoding='utf-8') 27 new_urls = set() 28 links = soup.find_all("a", href=re.compile(r"/item/\w+")) 29 for link in links: 30 new_urls.add(urljoin(url, link["href"])) 31 data = {"url": url, "new_urls": new_urls} 32 data["title"] = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1").get_text() 33 data["summary"] = soup.find("div", class_="lemma-summary").get_text() 34 except BaseException as e: 35 print(str(e)) 36 data = None 37 return data 38 39 def crawl(self, url, complete_callback): 40 future = self.thread_pool.submit(self._request_parse_runnable, url) 41 future.add_done_callback(complete_callback) 42 43 44 class OutPutThreadPool(object): 45 ''' 46 ��������߳���Ϊ5���̳߳ض�������ȡ�����̳߳ؽ�����в��������洢�� 47 ''' 48 def __init__(self): 49 self.thread_pool = ThreadPoolExecutor(max_workers=5) 50 51 def _output_runnable(self, crawl_result): 52 try: 53 url = crawl_result['url'] 54 title = crawl_result['title'] 55 summary = crawl_result['summary'] 56 save_dir = 'output' 57 print('start save %s as %s.txt.' % (url, title)) 58 if os.path.exists(save_dir) is False: 59 os.makedirs(save_dir) 60 save_file = save_dir + os.path.sep + title + '.txt' 61 if os.path.exists(save_file): 62 print('file %s is already exist!' % title) 63 return 64 with open(save_file, "w") as file_input: 65 file_input.write(summary) 66 except Exception as e: 67 print('save file error.'+str(e)) 68 69 def save(self, crawl_result): 70 self.thread_pool.submit(self._output_runnable, crawl_result) 71 72 73 class CrawlManager(object): 74 ''' 75 ��������࣬���������ȡ�����̳߳ؼ��洢�̳߳� 76 ''' 77 def __init__(self): 78 self.crawl_pool = CrawlThreadPool() 79 self.output_pool = OutPutThreadPool() 80 81 def _crawl_future_callback(self, crawl_url_future): 82 try: 83 data = crawl_url_future.result() 84 for new_url in data['new_urls']: 85 self.start_runner(new_url) 86 self.output_pool.save(data) 87 except Exception as e: 88 print('Run crawl url future thread error. '+str(e)) 89 90 def start_runner(self, url): 91 self.crawl_pool.crawl(url, self._crawl_future_callback) 92 93 94 if __name__ == '__main__': 95 root_url = 'http://baike.baidu.com/item/Android' 96 CrawlManager().start_runner(root_url)
��Ч�ʱ����ϵ�е�һƪ���İٿ������ֱ�ߵIJ����ٸ��ˣ��ವģ����������ֽ�ͼ���£�
3-2 ���������ʵս
ɶҲ����˵��������߳������ţ��Ч����Ȼ�ÿ�����������ţ��֮���ˣ�Ҳһ���������˵ɶ�������˵���㹻���ˣ�����ߣ�����Ӿ����ϴ��룬Ҳ������ɶ���棬��ע�;��У����£�
1 import os 2 from concurrent.futures import ProcessPoolExecutor 3 from urllib import request 4 import re 5 from urllib.parse import urljoin 6 from bs4 import BeautifulSoup 7 ''' 8 ʹ�ý��̳���ȡ�������洢�������ʾ�� 9 ��ȡ�ٶȰٿ�Android������鼰�ô������Ӵ����ļ����Ϣ��������������ǰĿ¼��outputĿ¼ 10 ''' 11 12 13 class CrawlProcess(object): 14 ''' 15 ��Ͻ��̳ؽ���URL������ȡ����������� 16 ����ͨ��crawl������complete_callback����������ȡ��������ص� 17 ''' 18 def _request_parse_runnable(self, url): 19 print('start get web content from: ' + url) 20 try: 21 headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64)"} 22 req = request.Request(url, headers=headers) 23 content = request.urlopen(req).read().decode("utf-8") 24 soup = BeautifulSoup(content, "html.parser", from_encoding='utf-8') 25 new_urls = set() 26 links = soup.find_all("a", href=re.compile(r"/item/\w+")) 27 for link in links: 28 new_urls.add(urljoin(url, link["href"])) 29 data = {"url": url, "new_urls": new_urls} 30 data["title"] = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1").get_text() 31 data["summary"] = soup.find("div", class_="lemma-summary").get_text() 32 except BaseException as e: 33 print(str(e)) 34 data = None 35 return data 36 37 def crawl(self, url, complete_callback, process_pool): 38 future = process_pool.submit(self._request_parse_runnable, url) 39 future.add_done_callback(complete_callback) 40 41 42 class OutPutProcess(object): 43 ''' 44 ��Ͻ��̳ض�������ȡ�������̽�����н��̳ش����洢�� 45 ''' 46 def _output_runnable(self, crawl_result): 47 try: 48 url = crawl_result['url'] 49 title = crawl_result['title'] 50 summary = crawl_result['summary'] 51 save_dir = 'output' 52 print('start save %s as %s.txt.' % (url, title)) 53 if os.path.exists(save_dir) is False: 54 os.makedirs(save_dir) 55 save_file = save_dir + os.path.sep + title + '.txt' 56 if os.path.exists(save_file): 57 print('file %s is already exist!' % title) 58 return None 59 with open(save_file, "w") as file_input: 60 file_input.write(summary) 61 except Exception as e: 62 print('save file error.'+str(e)) 63 return crawl_result 64 65 def save(self, crawl_result, process_pool): 66 process_pool.submit(self._output_runnable, crawl_result) 67 68 69 class CrawlManager(object): 70 ''' 71 ��������࣬���̳ظ���ͳһ����������ȡ�������洢���� 72 ''' 73 def __init__(self): 74 self.crawl = CrawlProcess() 75 self.output = OutPutProcess() 76 self.crawl_pool = ProcessPoolExecutor(max_workers=8) 77 self.crawl_deep = 100 #��ȡ��� 78 self.crawl_cur_count = 0 79 80 def _crawl_future_callback(self, crawl_url_future): 81 try: 82 data = crawl_url_future.result() 83 self.output.save(data, self.crawl_pool) 84 for new_url in data['new_urls']: 85 self.start_runner(new_url) 86 except Exception as e: 87 print('Run crawl url future process error. '+str(e)) 88 89 def start_runner(self, url): 90 if self.crawl_cur_count > self.crawl_deep: 91 return 92 self.crawl_cur_count += 1 93 self.crawl.crawl(url, self._crawl_future_callback, self.crawl_pool) 94 95 96 if __name__ == '__main__': 97 root_url = 'http://baike.baidu.com/item/Android' 98 CrawlManager().start_runner(root_url)
����Ч���Ͳ���˵�ˣ��������̳߳���ȡЧ�����ƣ�ֻ�ǻ�Ϊ�˽��̳���ȡ���ѡ�
5 ���������ܽ�
ɶ����˵����һƪһ�¸���е㲻���ڽ��ܲ������棬������ Python3 ������̻����ˣ��ӵ�������������������ǻ��Ǹ������������� Python3 �̳߳ء����̳صIJ�������С��������ȸ��С�������ȫ����Ȼ��ƪ�Բ������棨Python3 ������û�н���������ܣ����ǻ���Ŀ�Ĵﵽ�ˣ����ڲ�������ѧϰ����һ����Ĺ������ڴ�����Ŀ���Ǹ�����ѧ�ʵĶ�����Ҫ�ߵ�·���кܳ�������������ƪ���̵����ǾͿ����Լ�ȥ�����ֲ�ʽ����Ļ���ԭ������ʵ���Ƕ�������棬���о������ǿ����Լ�ȥ������ Python ���첽 IO ���ƣ��Dz��Ǻ��ģ���Ҳ����һ��ƪ����˵���Ķ�����
��ǩ��
��Ȩ��������վ���²��������磬������Ȩ������ϵ��west999com@outlook.com
�ر�ע�⣺��վ����ת���������۲�������վ�۵㣬��վ���ṩ����Ӱ��Ƭ���廭�������Ʒ������ʹ�ã�����ԭ������ϵ����Ȩ��ԭ��������

��һƪ��pythonѧϰ���ھ�ƪ��python���������
��һƪ��dz��ajaxԭ�����÷�
- python3����֮���������2���� 2019-08-13
- python3 ֮ �ַ�������С�ᣨUnicode��utf-8��gbk��gb2312�� 2019-08-13
- Python3��װimpala 2019-08-13
- С��������� Python ���棿 2019-08-13
- python day2-����ʵ��github��¼ 2019-08-13
IDC��Ѷ�� ������Ѷ ע����Ѷ �й���Ѷ vps��Ѷ ��վ����
��վ��Ӫ�� ��վ���� ��ӯ�� �����Ż� ��վ�ƹ� �����Դ
��վ���ˣ� �������� ���˽��� ���˵��� ������
��ҵ��Ѷ�� �������� ������Ϸ �������� ��洫ý
�����̣� Asp.Net��� Asp��� Php��� Xml��� Access Mssql Mysql ����
������������ Web������ Ftp������ Mail������ Dns������ ��ȫ����
�������ɣ� �������� Word Excel Powerpoint Ghost Vista QQ�ռ� QQ FlashGet Ѹ��
��ҳ������ FrontPages Dreamweaver Javascript css photoshop fireworks Flash
������ƣ� Java���� C/C++ VB delphi
