
sklearn datasets模块学习
2018-06-18 02:35:11来源:未知 阅读 ()

sklearn.datasets模块主要提供了一些导入、在线下载及本地生成数据集的方法,可以通过dir或help命令查看,我们会发现主要有三种形式:load_<dataset_name>、fetch_<dataset_name>及make_<dataset_name>的方法
① datasets.load_<dataset_name>:sklearn包自带的小数据集
- In [2]: datasets.load_*?
- datasets.load_boston#波士顿房价数据集
- datasets.load_breast_cancer#乳腺癌数据集
- datasets.load_diabetes#糖尿病数据集
- datasets.load_digits#手写体数字数据集
- datasets.load_files
- datasets.load_iris#鸢尾花数据集
- datasets.load_lfw_pairs
- datasets.load_lfw_people
- datasets.load_linnerud#体能训练数据集
- datasets.load_mlcomp
- datasets.load_sample_image
- datasets.load_sample_images
- datasets.load_svmlight_file
- datasets.load_svmlight_files
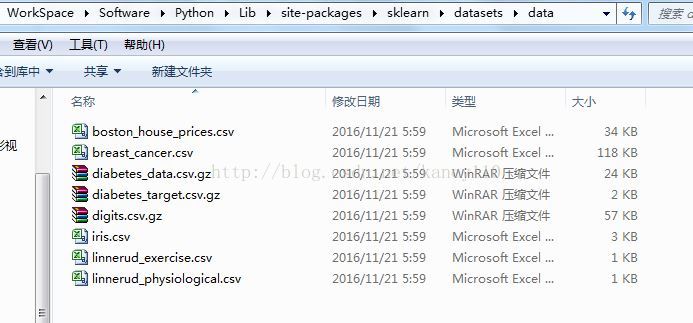
数据集文件在sklearn安装目录下datasets\data文件下
②datasets.fetch_<dataset_name>:比较大的数据集,主要用于测试解决实际问题,支持在线下载
- In [3]: datasets.fetch_*?
- datasets.fetch_20newsgroups
- datasets.fetch_20newsgroups_vectorized
- datasets.fetch_california_housing
- datasets.fetch_covtype
- datasets.fetch_kddcup99
- datasets.fetch_lfw_pairs
- datasets.fetch_lfw_people
- datasets.fetch_mldata
- datasets.fetch_olivetti_faces
- datasets.fetch_rcv1
- datasets.fetch_species_distributions
下载下来的数据,默认保存在~/scikit_learn_data文件夹下,可以通过设置环境变量SCIKIT_LEARN_DATA修改路径,datasets.get_data_home()获取下载路径
- In [5]: datasets.get_data_home()
- Out[5]: 'G:\\datasets'
③datasets.make_*?:构造数据集
- In [4]: datasets.make_*?
- datasets.make_biclusters
- datasets.make_blobs
- datasets.make_checkerboard
- datasets.make_circles
- datasets.make_classification
- datasets.make_friedman1
- datasets.make_friedman2
- datasets.make_friedman3
- datasets.make_gaussian_quantiles
- datasets.make_hastie_10_2
- datasets.make_low_rank_matrix
- datasets.make_moons
- datasets.make_multilabel_classification
- datasets.make_regression
- datasets.make_s_curve
- datasets.make_sparse_coded_signal
- datasets.make_sparse_spd_matrix
- datasets.make_sparse_uncorrelated
- datasets.make_spd_matrix
- datasets.make_swiss_roll
下面以make_regression()函数为例,首先看看函数语法:
make_regression(n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, effective_rank=None, tail_strength=0.5, noise=0.0, shuffle=True, coef=False, random_state=None)
参数说明:
n_samples:样本数
n_features:特征数(自变量个数)
n_informative:相关特征(相关自变量个数)即参与了建模型的特征数
n_targets:因变量个数
bias:偏差(截距)
coef:是否输出coef标识
- In [7]: data = datasets.make_regression(5,3,2,2,1.0,coef=True)
- ...: data
- ...:
- Out[7]:
- (array([[-0.64470031, 2.24028402, -2.26147027],
- [-0.09554589, 1.4653344 , -0.8882202 ],
- [-1.36214673, 0.08935031, 0.66733545],
- [-1.30553824, 1.62553382, 0.65693763],
- [-0.81528358, 0.81659886, 1.32412053]]),
- array([[ 177.32114822, -42.34640341],
- [ 127.51997766, -1.98105497],
- [ -37.82547178, -104.69214796],
- [ 100.19123506, -95.62163254],
- [ 45.35860387, -59.94143654]]),
- array([[ 34.3135368 , 77.79161196],
- [ 88.57943632, 3.03795085],
- [ 0. , 0. ]]))
上述输出结果:元组中的三个数组分别对应输入数据X,输出数据y,coef对应数组
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

下一篇:Python 正则介绍
- python3 enum模块的应用 2019-08-13
- 利用python自动生成verilog模块例化模板 2019-08-13
- Python sklearn拆分训练集、测试集及预测导出评分 决策树 2019-08-13
- Python random模块(以后用到一个再更新一个) 2019-07-24
- xadmin进行全局配置(修改模块名为中文以及其他自定义的操作 2019-07-24
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
