
浏览器的日常生活
2018-06-24 00:24:00来源:未知 阅读 ()

闲言少叙,直入正题吧。我们作为前端工程师,每天就是跟页面打交道。页面呢又是在浏览器中展现的。每天开发项目时,一遍遍的刷新浏览器,来看页面的展现效果。
不过我们可曾想过,浏览器是如何工作将我们开发的项目转化为页面的呢?为什么我们在浏览器输入一个URL,点击回车就能够展现出一个页面呢?
可能有人会说,不就是浏览器发送了一个请求,下载了一个HTML,然后解析渲染就好了。对,其实就是这样的。但是浏览器是如何请求的呢?又是怎么渲染的呢?
下面我们带着问题一起来探讨一下:
1、浏览器在发起请求时首先会做什么?
答,查找本地缓存
答案很多同学应该都知道了,那当然是根据URL查找本地缓存啦!先看本地缓存中是否有当前请求的URL的内容,如果存在,当然好了,直接用就好了。如果不存在,那就得去向服务器请求该URL了。
但是同学们,你可别小看了这个本地缓存,这里边可有大学问呢。首先让我们回顾一下浏览器的缓存标识字段都有哪些。
- Cache-control,指明当前资源的有效期,控制浏览器是否直接从浏览器缓存取数据还是重新发请求到服务器取数据。
- Expires,Web服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据,而无需再次请求。Expires是HTTP1.0的东西,所以它的作用我们可以基本忽略了。
- Last-Modified,标示请求资源的最后修改时间。
- Etag,web服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识。
这么多缓存标识,判断时肯定得有个优先级吧,那是肯定的,Cache-control优先级高于Expires,Etag优先级高于Last-Modified。说这么多,直接上图吧,看下图更清晰:
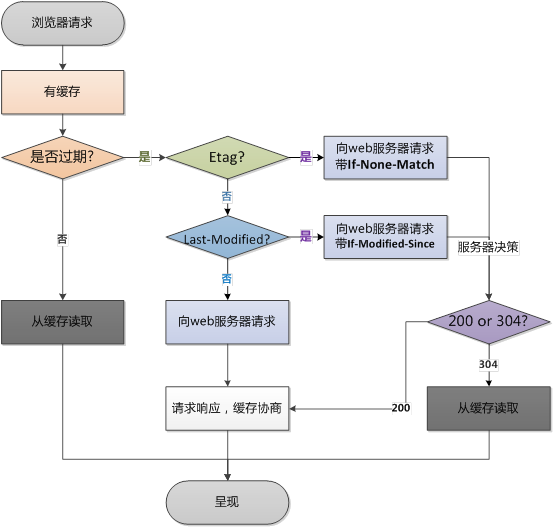
看完上图我相信大家应该对浏览器缓存的机制就了解了,那我们接着研究浏览器下一步会做什么?
2、浏览器查找完缓存之后接下来要做的是什么呢?
答,DNS query
首先客户机将域名查询请求发送到本地DNS服务器,本地DNS服务器先在之前的记录(缓存)中查找,如果有缓存,则直接利用缓存进行解析,如果没有缓存,则进入本地的缓存的寻找。如果本地服务器不能在本地找到缓存,则将请求发送到根域名DNS服务器。
DNS服务器在拿到我们的域名后,会将它解析成IP地址返回给浏览器,这样浏览器就能直接定位到要请求的服务器的地址了。
3、找到服务器地址之后肯定就是向服务器发送请求,
建立连接,这个不用问了。
这样根据IP和端口,浏览器就开始跟服务器建立TCP连接啦。看到TCP连接,我们就想到了三次握手。
三次握手简化版:
甲:你瞅啥?
乙:瞅你咋地?
甲:不服来一发数据啊。
甲和乙就来一发数据了。
当然啦,连接建立后,那就是愉快的互相发数据啦,那么问题来了。
4、浏览器在接收到服务器返回的数据后会怎么做呢?
答,解析数据,生成渲染树
渲染展现页面是肯定的啦,关键是如何渲染。我们先来看一下浏览器的简单处理步骤:
(1)解析HTML/SVG/XHTML,build DOM树。
(2)解析CSS,build CSSOM树。
(3)build render树。render树并不等同于DOM树,因为一些像Header或display:none的东西就没必要放在render树中了。
(4)reflow。计算每个Element在设备中显示的具体位置。
(5)paint。最后通过调用操作系统Native GUI的API绘制。
parse content。
- 根据HTTP响应返回的数据来对页面的编码进行解码。
- HTTP头中的Content-Type:text/html;charset=信息,这是最高的优先级判断的;
- 其次网页本身meta,header中Content-Type信息的charset部分,这个主要针对的是HTTP头未指定编码或者我们的本地文件;
- 如果前面说的两条都没有找到,浏览器还给我们开了一个功能,在菜单里一般允许用户强制指定编码;部分浏览器(比如Firefox)还可以选择编码自动检测,使用基于统计的方法判断未定编码。
- 编码确定后,网页就被解码成了Unicode字符流,可以进行HTML解析。一个字符一个字符解析,边下载边解析。
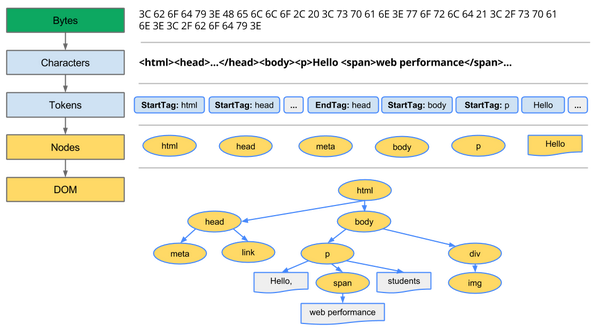
build dom tree。
转换(Conversion):浏览器读取HTML的原始字节,然后根据指定的编码规则转换成单独的字符(比如按UTF-8编码)。
标记分解(Tokenizing):浏览器将字符串按照W3C的HTML5标准转换成确定的标记,比如带尖括号的字符。每个标记都有特定的意义以及一套规则。
词法分析(Lexing):分解出来的标记被转换成能定义其属性和规则的对象。
DOM构造:最终由于HTML标记创建出来的对象被关联到一个树形数据结构。这颗树会反映在原先标签里定义的父子关系,比如HTML对象就是body对象的父对象,body对象又是p 对象的父对象等等。 我们看下图吧,更直观一些:
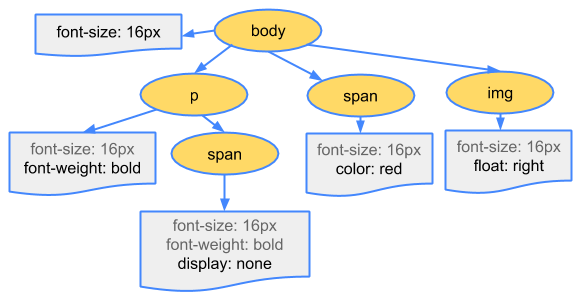
build CSSOM tree
过程跟构建dom tree一样,看下图吧:
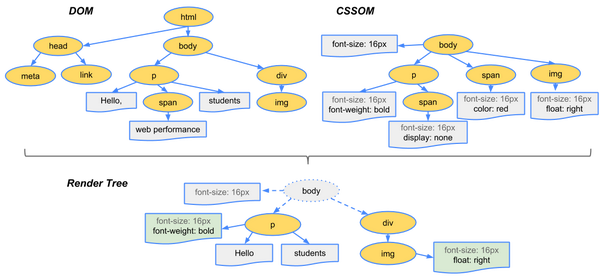
build render tree
浏览器在渲染时只有同时具备DOM和CSSOM才能来构造渲染树。大致步骤是这样的:
- 从DOM树的根节点开始,遍历所有的可视节点。
- 有些不可见的元素会被忽略,因为他们不会影响我们页面的渲染结果,例如元数据标签,脚本标签等。还有一些通过CSS样式隐藏掉的元素也会被忽略掉。比如设置了“display:none”属性的元素。值得一提的是“visibility:hidden”和“display:none”是不同的,前者会在页面上隐藏元素,但是在最终的布局上仍然会占据原来的空间,其实就是一片空白。而后者则是将元素在页面的渲染树上删除,在最终布局上就没有这个节点了。
- 对于DOM树中每个节点,从CSSOM中寻找对应的样式规则,并添加到新创建的一棵渲染树节点上。
- 最后输出可视的节点,以及该节点上计算出来的样式,即最终版渲染树。
还是那句话,看下图:
5、生成渲染树之后该做什么了?
答,回流,绘制
- reflow(回流)
现在我们已经得到了渲染树,并且知道哪个节点要展示,并且展示成什么样子。但是这时候我们并不知道这些节点在当前设备中的具体位置和尺寸,没错,这正是reflow阶段要做的工作,从根节点递归调用,计算每一个元素的大小、位置等,给每个节点所应该出现在屏幕上的精确坐标。
- paint(绘制)
到这里,我们已经知道了哪些节点是可视的、它们的样式和它们的几何外观,以及它们在设备上的精准位置,终于可以绘制了。在paint阶段,浏览器通过调用操作系统Native GUI的API绘制每一个像素点,更新显存,给显示器发送信号,显示器根据得到的信号进行显示。
恭喜你,到这里你已经可以看到页面啦!那么我们的介绍到这里也要结束了,如果有不对的地方,欢迎批评指正,有不同的想法,也欢迎来跟我们交流。
如果你喜欢我们的文章,关注我们的公众号和我们互动吧。

我们是转转FE团队,欢迎大家关注公众号 大转转FE 。更多的了解我们
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

上一篇:数据存储
下一篇:仿微信抢红包(js 转)
- JS判断浏览器是否安装flash插件的简单方法 2020-03-12
- 使用JS在浏览器中判断当前网络连接状态的几种方法 2020-03-12
- Js操作DOM元素及获取浏览器高宽的简单方法 2019-12-31
- 浏览器上实现右键菜单的方法 2019-10-25
- 浏览器窗口上添加遮罩层的方法 2019-10-16
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
