
HashMap源码分析--jdk1.8
2019-08-16 12:05:55来源:博客园 阅读 ()

HashMap源码分析--jdk1.8
JDK1.8
ArrayList源码分析--jdk1.8
LinkedList源码分析--jdk1.8
HashMap源码分析--jdk1.8
AQS源码分析--jdk1.8
ReentrantLock源码分析--jdk1.8
HashMap概述
1. HashMap是可以动态扩容的数组,基于数组、链表、红黑树实现的集合。
2. HashMap支持键值对取值、克隆、序列化,元素无序,key不可重复value可重复,都可为null。
3. HashMap初始默认长度16,超出扩容2倍,填充因子0.75f。
4.HashMap当链表的长度大于8的且数组大小大于64时,链表结构转变为红黑树结构。
HashMap数据结构
数据结构是集合的精华所在,数据结构往往也限制了集合的作用和侧重点,了解各种数据结构是我们分析源码的必经之路。
HashMap的数据结构如下:数组+链表+红黑树
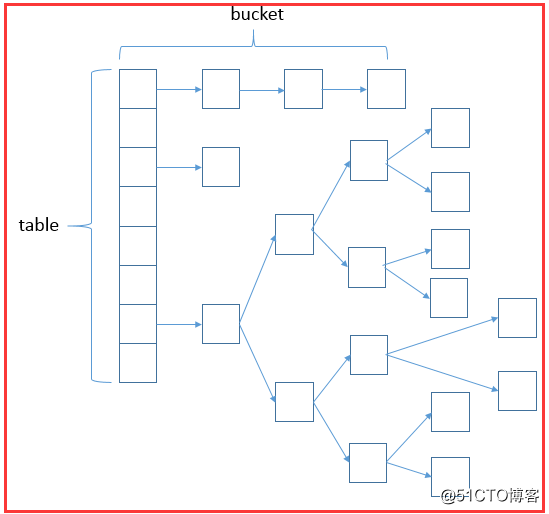
HashMap源码分析
/*
* 用数组+链表+红黑树实现的集合,支持键值对查找
*/
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
/**
* 默认初始容量-必须是2的幂
* 1*2的4次方 默认长度16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
/**
* 最大容量
* 1*2的30次方 最大容量1073741824
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 默认的填充因子 0.75
* 负载因子0.75是对空间和时间效率的一个平衡选择,建议大家不要修改,除非在时间和空间比较特殊的情况下,
* 如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值;
* 相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 当桶(bucket)上的节点数大于这个值时会转成红黑树
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 当桶(bucket)上的节点数小于这个值时树转链表
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* 桶中结构转化为红黑树对应的table的最小大小
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* Node是单向链表,它实现了Map.Entry接口
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//构造函数Hash值 键 值 下一个节点
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
// 实现接口定义的方法,且该方法不可被重写
// 设值,返回旧值
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
//构造函数Hash值 键 值 下一个节点
/*
* 重写父类Object的equals方法,且该方法不可被自己的子类再重写
* 判断相等的依据是,只要是Map.Entry的一个实例,并且键键、值值都相等就返回True
*/
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
HashMap继承和实现分析
HashMap extends AbstractMap
AbstractMap extends Object
java中所有类都继承Object,所以HashMap的继承结构如上图。
1. AbstractMap是一个抽象类,实现了Map<K,V>接口,Map<K,V>定义了一些Map(K,V)键值对通用方法,而AbstractMap抽象类中可以有抽象方法,还可以有具体的实现方法,AbstractMap实现接口中一些通用的方法,实现了基础的/get/remove/containsKey/containsValue/keySet方法,HashMap再继承AbstractMap,拿到通用基础的方法,然后自己在实现一些自己特有的方法,这样的好处是:让代码更简洁,继承结构最底层的类中通用的方法,减少重复代码,从上往下,从抽象到具体,越来越丰富,可复用。
2.HashMap实现了Map<K,V>、Cloneable、Serializable接口
1)Map<K,V>接口,定义了Map键值对通用的方法,1.8中为了加强接口的能力,使得接口可以存在具体的方法,前提是方法需要被default或static关键字所修饰,Map中实现了一些通用方法实现,使接口更加抽象。
2)Cloneable接口,可以使用Object.Clone()方法。
3)Serializable接口,序列化接口,表明该类可以被序列化,什么是序列化?简单的说,就是能够从类变成字节流传输,反序列化,就是从字节流变成原来的类

HashMap核心方法分析
1. put方法(10种实现)--增/修改




1)V put(K key, V value);//map添加元素
/**
* 新增元素
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* onlyIfAbsent默认传false,覆盖更改现有值
* onlyIfAbsent传true,不覆盖更改现有值
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果table为空 或者 长度为0
if ((tab = table) == null || (n = tab.length) == 0)
//扩容
n = (tab = resize()).length;
//计算index,并对null做处理
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素
else {
Node<K,V> e; K k;
//如果key存在 直接覆盖 value
// 比较桶中第一个元素(数组中的结点)的hash值相等,key相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 将第一个元素赋值给e,用e来记录
e = p;
//如果table[i]是红黑树 直接在红黑树中插入
// hash值不相等,即key不相等;为红黑树结点
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//如果是链表 则遍历链表
else {
// 在链表最末插入结点
for (int binCount = 0; ; ++binCount) {
// 到达链表的尾部
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
// 结点数量达到阈值,转化为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// 跳出循环
break;
}
// 判断链表中结点的key值与插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
// 表示在桶中找到key值、hash值与插入元素相等的结点
if (e != null) { // existing mapping for key
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null
if (!onlyIfAbsent || oldValue == null)
//用新值替换旧值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 结构性修改
++modCount;
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调,用来回调移除最早放入Map的对象(LinkedHashMap中实现了,HashMap中为空实现)
afterNodeInsertion(evict);
return null;
}2)putAll(Map<? extends K, ? extends V> m);//添加Map全部元素
/**
* 添加Map全部元素
*/
public void putAll(Map<? extends K, ? extends V> m) {
putMapEntries(m, true);
}
/**
* Implements Map.putAll and Map constructor
* @param m the map
* @param evict false when initially constructing this map, else
* true (relayed to method afterNodeInsertion).
*/
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// 判断table是否已经初始化
if (table == null) { // pre-size
// 未初始化,s为m的实际元素个数
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// 计算得到的t大于阈值,则初始化阈值
if (t > threshold)
threshold = tableSizeFor(t);
}
// 已初始化,并且m元素个数大于阈值,进行扩容处理
else if (s > threshold)
resize();
// 将m中的所有元素添加至HashMap中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
/**
* 扩容
* ①.在jdk1.8中,resize方法是在hashmap中的键值对大于阀值时或者初始化时,就调用resize方法进行扩容;
* ②.每次扩展的时候,都是扩展2倍:16、32、64、128...
* ③.扩展后Node对象的位置要么在原位置,要么移动到原偏移量两倍(2次幂)的位置。
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;//oldTab指向hash桶数组
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {//如果oldCap大于的话,就是hash桶数组不为空
if (oldCap >= MAXIMUM_CAPACITY) {//如果大于最大容量了,就赋值为整数最大的阀值
threshold = Integer.MAX_VALUE;
return oldTab;
}
//如果当前hash桶数组的长度在扩容后仍然小于最大容量 并且oldCap大于默认值16,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold 双倍扩容阀值threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//新建hash桶数组
table = newTab;//将新数组的值复制给旧的hash桶数组
if (oldTab != null) {//进行扩容操作,复制Node对象值到新的hash桶数组
//把每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {//如果旧的hash桶数组在j结点处不为空,复制给e
oldTab[j] = null;//将旧的hash桶数组在j结点处设置为空,方便gc
if (e.next == null)//如果e后面没有Node结点
newTab[e.hash & (newCap - 1)] = e;//直接对e的hash值对新的数组长度求模获得存储位置
else if (e instanceof TreeNode)//如果e是红黑树的类型,那么添加到红黑树中
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order 链表优化重hash的代码块
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;//将Node结点的next赋值给next
if ((e.hash & oldCap) == 0) {//如果结点e的hash值与原hash桶数组的长度作与运算为0 原索引
if (loTail == null)//如果loTail为null
loHead = e;//将e结点赋值给loHead
else
loTail.next = e;//否则将e赋值给loTail.next
loTail = e;//然后将e复制给loTail
}
// 原索引+oldCap
else {//如果结点e的hash值与原hash桶数组的长度作与运算不为0
if (hiTail == null)//如果hiTail为null
hiHead = e;//将e赋值给hiHead
else
hiTail.next = e;//如果hiTail不为空,将e复制给hiTail.next
hiTail = e;//将e复制个hiTail
}
} while ((e = next) != null);//直到e为空
//原索引放到bucket里
if (loTail != null) {//如果loTail不为空
loTail.next = null;//将loTail.next设置为空
newTab[j] = loHead;//将loHead赋值给新的hash桶数组[j]处
}
//原索引+oldCap放到bucket里
if (hiTail != null) {//如果hiTail不为空
hiTail.next = null;//将hiTail.next赋值为空
newTab[j + oldCap] = hiHead;//将hiHead赋值给新的hash桶数组[j+旧hash桶数组长度]
}
}
}
}
}
return newTab;
}3)V putIfAbsent(K key, V value);//如果key存在,则跳过,不覆盖value值,onlyIfAbsent传true,不覆盖更改现有值
/**
* 如果key存在则跳过,不覆盖value值,onlyIfAbsent传true,不覆盖更改现有值
* 如果key不存在则put
* @param key
* @param value
* @return
*/
@Override
public V putIfAbsent(K key, V value) {
return putVal(hash(key), key, value, true, true);
}4)merge(K key, V value,BiFunction<? super V, ? super V, ? extends V> remappingFunction);//用某种方法更新原来的value值
/**
* 用某种方法更新原来的value值
* BiFunction支持函数式变成,lambda表达式,如:String::concat拼接
* @param key
* @param value
* @param remappingFunction
* @return
*/
@Override
public V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
if (value == null)
throw new NullPointerException();
if (remappingFunction == null)
throw new NullPointerException();
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null;// 该key原来的节点对象
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0)//判断是否需要扩容
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
if (first instanceof TreeNode)// 取出old Node对象
old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key);
else {
Node<K,V> e = first; K k;
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
old = e;
break;
}
++binCount;
} while ((e = e.next) != null);
}
}
if (old != null) {//如果 old Node 存在
V v;
if (old.value != null)
// 如果old存在,执行lambda,算出新的val并写入old Node后返回。
v = remappingFunction.apply(old.value, value);
else
v = value;
if (v != null) {
old.value = v;
afterNodeAccess(old);
}
else
removeNode(hash, key, null, false, true);
return v;
}
if (value != null) {
//如果old不存在且传入的newVal不为null,则put新的kv
if (t != null)
t.putTreeVal(this, tab, hash, key, value);
else {
tab[i] = newNode(hash, key, value, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
++modCount;
++size;
afterNodeInsertion(true);
}
return value;
}5)compute(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction);//根据已知的 k v 算出新的v并put
/**
* 根据已知的 k v 算出新的v并put。
* 如果根据key获取的oldVal为空则lambda中涉及到oldVal的计算会报空指针。
* 如:map.compute("a", (key, oldVal) -> oldVal + 1); 如果oldVal为null,则空指针
* 源码和merge类似
* BiFunction返回值作为新的value,BiFunction有二个参数
* @param key
* @param remappingFunction
* @return
*/
@Override
public V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
if (remappingFunction == null)
throw new NullPointerException();
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null;
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0)
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
if (first instanceof TreeNode)
old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key);
else {
Node<K,V> e = first; K k;
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
old = e;
break;
}
++binCount;
} while ((e = e.next) != null);
}
}
V oldValue = (old == null) ? null : old.value;
V v = remappingFunction.apply(key, oldValue);
if (old != null) {
if (v != null) {
old.value = v;
afterNodeAccess(old);
}
else
removeNode(hash, key, null, false, true);
}
else if (v != null) {
if (t != null)
t.putTreeVal(this, tab, hash, key, v);
else {
tab[i] = newNode(hash, key, v, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
++modCount;
++size;
afterNodeInsertion(true);
}
return v;
}6)computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction);//当key不存在时才put,如果key存在则无效
/**
* 当key不存在时才put,如果key存在则无效
* 如:computeIfAbsent(keyC, k -> genValue(k));
* Function返回值作为新的value,Function只有一个参数
* @param key
* @param mappingFunction
* @return
*/
@Override
public V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction) {
if (mappingFunction == null)
throw new NullPointerException();
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null;
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0)
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
if (first instanceof TreeNode)
old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key);
else {
Node<K,V> e = first; K k;
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
old = e;
break;
}
++binCount;
} while ((e = e.next) != null);
}
V oldValue;
if (old != null && (oldValue = old.value) != null) {
afterNodeAccess(old);
return oldValue;
}
}
V v = mappingFunction.apply(key);
if (v == null) {
return null;
} else if (old != null) {
old.value = v;
afterNodeAccess(old);
return v;
}
else if (t != null)
t.putTreeVal(this, tab, hash, key, v);
else {
tab[i] = newNode(hash, key, v, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
++modCount;
++size;
afterNodeInsertion(true);
return v;
}7)computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction);//compute方法的补充,如果key存在,则覆盖新的BiFunction计算出的value值,如果不存在则跳过
/**
* compute方法的补充,如果key存在,则覆盖新的BiFunction计算出的value值,如果不存在则跳过
* @param key
* @param remappingFunction
* @return
*/
public V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
if (remappingFunction == null)
throw new NullPointerException();
Node<K,V> e; V oldValue;
int hash = hash(key);
if ((e = getNode(hash, key)) != null &&
(oldValue = e.value) != null) {
V v = remappingFunction.apply(key, oldValue);
if (v != null) {
e.value = v;
afterNodeAccess(e);
return v;
}
else
removeNode(hash, key, null, false, true);
}
return null;
}8)V replace(K key, V value);//替换新值
/**
* 如果key存在不为空,则替换新的value值
*/
@Override
public V replace(K key, V value) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) != null) {
V oldValue = e.value;
e.value = value;
afterNodeAccess(e);
return oldValue;
}
return null;
}9)replace(K key, V oldValue, V newValue);//判断oldValue是否是当前key的值,再替换新值
/**
* 如果key存在不为空并且oldValue等于当前key的值,则替换新的value值
*/
@Override
public boolean replace(K key, V oldValue, V newValue) {
Node<K,V> e; V v;
if ((e = getNode(hash(key), key)) != null &&
((v = e.value) == oldValue || (v != null && v.equals(oldValue)))) {
e.value = newValue;
afterNodeAccess(e);
return true;
}
return false;
}10)replaceAll(BiFunction<? super K, ? super V, ? extends V> function);//替换新值
/**
* 根据lambda函数替换符合规则的值
*/
@Override
public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
Node<K,V>[] tab;
if (function == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
e.value = function.apply(e.key, e.value);
}
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}总结:
正常情况下会扩容2倍,特殊情况下(新扩展数组大小已经达到了最大值)则只取最大值1 << 30。
2.remove方法(2种重载实现)--删

1)V remove(Object key); //根据key 删除元素
/**
* 根据key 删除元素
*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
* Implements Map.remove and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to match if matchValue, else ignored
* @param matchValue if true only remove if value is equal
* @param movable if false do not move other nodes while removing
* @return the node, or null if none
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}2)remove(Object key, Object value); //根据key,value 删除元素
/**
* 根据key,value 删除元素
*/
@Override
public boolean remove(Object key, Object value) {
return removeNode(hash(key), key, value, true, true) != null;
}3.get方法(2种实现)--查

/**
* 返回指定的值
*/
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* @author jiaxiaoxian
* @date 2019年2月12日
* 如果key不为空则返回key的值,否则返回默认值
*/
@Override
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? defaultValue : e.value;
}4.keySet方法--返回所有key,以Set结构返回
/**
* 返回所有key,以Set结构返回
*/
public Set<K> keySet() {
Set<K> ks;
return (ks = keySet) == null ? (keySet = new KeySet()) : ks;
}5.clone方法--克隆
/**
* 复制,返回此HashMap 的浅拷贝
*/
@SuppressWarnings("unchecked")
@Override
public Object clone() {
HashMap<K,V> result;
try {
result = (HashMap<K,V>)super.clone();
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
result.reinitialize();
result.putMapEntries(this, false);
return result;
}7.clear方法--清空HashMap
/**
* 清空HashMap
*/
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}8.containsKey方法--是否存在此key
/**
* 是否存在此key
*/
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}9.containsValue方法--是否存在此value
/**
* 是否存在此value
*/
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}10.entrySet方法--返回key,value的Set结果
/**
* 返回key,value的Set结果
*/
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new EntrySet()) : es;
}HashMap总结
1)HashMap的key、value都可以存放null,key不可重复,value可重复,是数组链表红黑树的数据结构。
2)HashMap区别于数组的地方在于能够自动扩展大小,其中关键的方法就是resize()方法,扩容为2倍。
3)HashMap由于本质是数组,在不冲突的情况下,查询效率很高,hash冲突后会形成链表,查找时多一层遍历,当链表长度到8并且数组长度大于64,转成红黑树存储,提高查询效率。
4)初始化数组时推荐给初始长度,反复扩容会增加时耗,影响性能效率,HashMap需要注意负载因子0.75f,初始16,当长度大于(16*0.75)12的时候会扩容为32,所以初始长度设置需要却别对待。
©著作权归作者所有:来自51CTO博客作者jiazhipeng12的原创作品,如需转载,请注明出处,否则将追究法律责任原文链接:https://www.cnblogs.com/hackerxian/p/11316504.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- 你说研究过Spring里面的源码,循环依赖你会么? 2020-06-09
- 通俗理解spring源码(六)―― 默认标签(import、alias、be 2020-06-07
- HashMap:源代码(构造方法、put、resize、get、remove、rep 2020-06-04
- 数据结构:用实例分析ArrayList与LinkedList的读写性能 2020-06-04
- HashMap1.7和1.8,红黑树原理! 2020-06-03
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
