
实现万行级数据读取优化
2019-08-16 11:37:38来源:博客园 阅读 ()

实现万行级数据读取优化
xl_echo编辑整理,欢迎转载,转载请声明文章来源。欢迎添加echo微信(微信号:t2421499075)交流学习。 百战不败,依不自称常胜,百败不颓,依能奋力前行。——这才是真正的堪称强大!!
---
#### 业务场景:
基于导出的功能上,要求一次性查询10w条数据。但是这个10w的开始值和结束值不固定(比如:startNum = 123; endNum = 100123;)
* 难点一:
dubbox时间超时规定为1s,服务调用图如下:
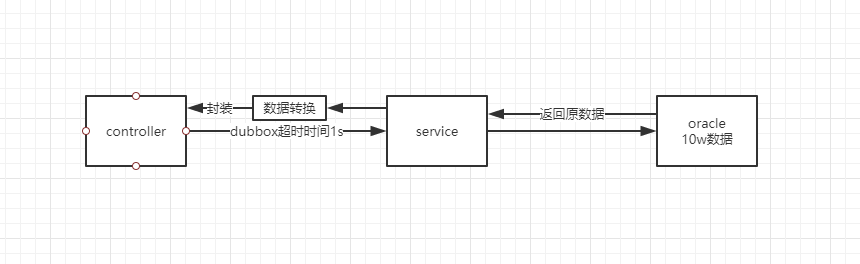
* 难点二:
数据封装转换性能消耗较高,目前使用的BeanUtils
* 难点三:
并发能力很弱,在分割查询的过程中,如果有其他的服务进入,很容易导致数据混乱
公司使用的数据库为oracle,目前我自己实现的查询功能总耗时8s。这个时间能不能再次缩短?有没有比较好的方案对数据分割查询?
#### 对于JDBC batchsize 和 fetchsize的一次尝试
Batch和Fetch两个特性非常重要,Batch相当于JDBC的写缓冲,Fetch相当于读缓冲。在加入这两个特性之后,查询10w条尝试,根据描述,能个提升4倍的时间。参考文章:http://blog.sina.com.cn/s/blog_9f8ffdaf0102x3nf.html
将代码摘抄之后,修改数据库连接的账户密码。单独使用检查代码是否能够独立运行,main,报错如下:
```
Exception in thread "main" java.lang.ClassNotFoundException: oracle.jdbc.OracleDriver
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at com.example.mybatisplusdemo.temp.Test.fetchRead(Test.java:74)
at com.example.mybatisplusdemo.temp.Test.main(Test.java:22)
```
###### 采坑一:
测试的功能为一个完整的springboot工程,当看到报错的的行数的时候,发现指向的是下面这一行
```java
Class.forName("oracle.jdbc.OracleDriver");
```
这个错其实提示很明显,就是找不到驱动包,我们只需要在maven中添加一个oracle的依赖即可。
```xml
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc6</artifactId>
<version>11.2.0.3</version>
</dependency>
```
当我加入依赖之后,一切都可以照常执行了。测试数据我造了10w数据,发现如果使用fetchsize和不使用,性能确实相差4倍左右的样子。同时如果数据多一些,可能效果还会明显一点。但是同时又出现了新的问题:测试环境和生产环境使用的是两套数据库,公司对生产环境保密很严,拿不到生产环境的密码,如果上线会导致功能出现问题。
###### 采坑二:
多环境开发和上线需要多次修改代码。这里其实就已经卡住了,不能再次往下进行。如果可以这么用的小伙伴可以考虑编写多环境的适配器。
> 反过来想,我们公司使用的mybatis,应该mybatis就会有对应的方法,而且只会比自己写jdbc要好点。
#### mybatis中使用fetchsize的一次尝试
其实冲上面的应用我们可以发现fetchsize其实的作用其实就是避免一次性将数据从数据库中拿出来, 以至于导致在加载到内存的数据过多,而内存溢出,或者导致缓慢。如果fetchsize的值为1w,是指定服务器一次返回1w条数据,如果总数为10w的话服务器就要发送10次
。
在mybatis中如果使用fetchsize其实也比较简单,比如在xml文件中需要使用sql的语句上直接加上fetchsize即可。如果不想简单处理,可以自己手写ResultHandler来分批处理结果集
。这里直接在xml上添加,示例如下:
```xml
<select id="selectAll" resultMap="BaseResultMap" parameterType="java.util.Map" fetchSize="10000">
select * from
(select c.*, ROWNUM rn FROM TABLE c where rownum <= #{endNumber})
where rn >= #{startNumber}
</select>
```
* 实测查询结果
> 这里使用的fetchsize设置值为1w,如果值越大估计性能提升会不断下降(这里属于博主猜测,没有验证哈,依据就是当不设置的时候就是一次性全部加载,那就相当于无限大,无限大的时候和1w比较值如下表格)
是否使用fetchsize | 查询第1次时间 | 查询第2次时间 | 查询第3次时间 | 查询第4次时间 | 查询第5次时间
-- | -- | -- | -- | -- | --
是 | 1010ms | 1269ms | 1091ms | 1147ms | 1028ms
否 | 4813ms | 4736ms | 4800ms | 4417ms | 4580ms
> 将fetchsize使用了之后,返回时间为1s左右,但是也只是优化了查询,还可以优化数据的封装。优化到这之后我们可以看到dubbox超时时间需要放宽。
###### 数据封装优化的思路Dozer --解决难点二
这里并没有实际去使用,因为需求中使用的时候发现BeanUtils去转换这一环节可以直接去掉。因为数据在传递的终点不是直接发送到前端,而是发送到controller,这种件如果去掉转换消耗会更小,后面在controller直接使用值会更快。
当然,后期可能会需要使用,因为业务肯定还会迭代这一块。只是目前可以省略。
Dozer是一个JavaBean映射工具库。据百度介绍,这是一款转换数据的神器。如果使用的话,需要加入它对应的依赖:
```xml
<dependency>
<groupId>net.sf.dozer</groupId>
<artifactId>dozer</artifactId>
<version>5.5.1</version>
</dependency>
```
如果要映射的两个对象有完全相同的属性名,那么一切都很简单。
```java
Mapper mapper = new DozerBeanMapper();
DestinationObject destObject = mapper.map(sourceObject, DestinationObject.class);
```
实际应用,项目需要返回VO类的数据,但你在mapper中是使用PO类,返回时需要转换
```java
Mapper announcementDozerMapper =new DozerBeanMapper();
/**
* @param announcementPo 原PO类的announcement类型
* @return 返回VO类的announcement类型
* @description 将announcement的PO类转化为VO类
**/
private AnnouncementVo doToVo(AnnouncementPo announcementPo){
if(announcementPo == null) {
return null;
}
AnnouncementVo vo = announcementDozerMapper.map(announcementPo, AnnouncementVo.class);
return vo;
}
```
- 注意:这里最好不要每次映射对象时都创建一个Mapper实例来工作,这样会产生不必要的开销。如果你不使用IoC容器(如:spring)来管理你的项目,那么,最好将Mapper定义为单例模式。
```java
public class DozerMapperConstant {
public static final Mapper dozerMapper = new org.dozer.DozerBeanMapper();
}
```
---
###### 当做完上面这些的时候发现,已经实现了已被的增速。从耗时8s到现在耗时只需要4s,这个是一个进步。当然这里,并不能满足,还需要进一步优化。
当优化完成之后,我们再一次去整合代码,数据库的查询从原来的分片查询直接更改为一次查询,响应时间为2s,但是这个时候,数据没有分片查询,导致在controller中调用接口的时候的接受数据是一次性接受的。所以10w数据的接受直接就走了rpc,最后报了如下错误:
```
com.alibaba.dubbo.remoting.TimeoutException: Waiting server-side response timeout.
java.lang.NullPointerException: null
```
仔细看是超时,这个时候发现其实又回到了原点,所有的优化在传输的时候又暂用回来了。最后去查看的时候才发现,10w的数据并不能直接通过rpc传输。这样会导致调用失败,并不是上面的超时。
- dubbox传输数据最大值为8M,10w条数据肯定大于8M,所以这个时候查询的优化完成之后要再一次优化dubbox之间的传输。
这里遵循不添加中间件,只修改代码哈。这里就不展示代码了,最终采用的办法就是分片请求。
总结:
- fetchsize解决一次性查询时间慢的问题,性能提升4倍
- 减除转换,直接传递。了解Dozer,为后期的转化做准备
- dubbox调用,分片请求
欢迎打赏
---

原文链接:https://www.cnblogs.com/xlecho/p/11277509.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- DES/3DES/AES 三种对称加密算法实现 2020-06-11
- Flink 如何分流数据 2020-06-11
- 数据源管理 | Kafka集群环境搭建,消息存储机制详解 2020-06-11
- SpringBoot + Vue + ElementUI 实现后台管理系统模板 -- 后 2020-06-10
- Spring Boot 实现定时任务的 4 种方式 2020-06-10
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
