
Java:集合类的数据结构
2019-08-16 09:46:01来源:博客园 阅读 ()

Java:集合类的数据结构

本文源自参考《Think in Java》,多篇博文以及阅读源码的总结
前言
Java的集合其实就是各种基本的数据结构(栈,队列,hash表等),基于业务需求进而演变出的Java特有的数据结构(因为不仅仅是基本数据结构)。现在,我们以数据结构的视角来看看Java的集合到底是什么样子。并分析他们的性能。
一 JAVA集合体系
JAVA的集合体系分为两类,Collection接口和Map接口
主要分为三种:
- Set。无插入顺序的不重复数据集接口(集合演变而来)
- List。有插入顺序的数据集接口(队列演变而来)
- Map。Key-Value的键值对数据集接口(Hash表演变而来)
其中Set和List继承自Collection接口,Map则就是Map接口。
接口中都定义了一些基本增删改查的方法。
具体继承体系如下图:
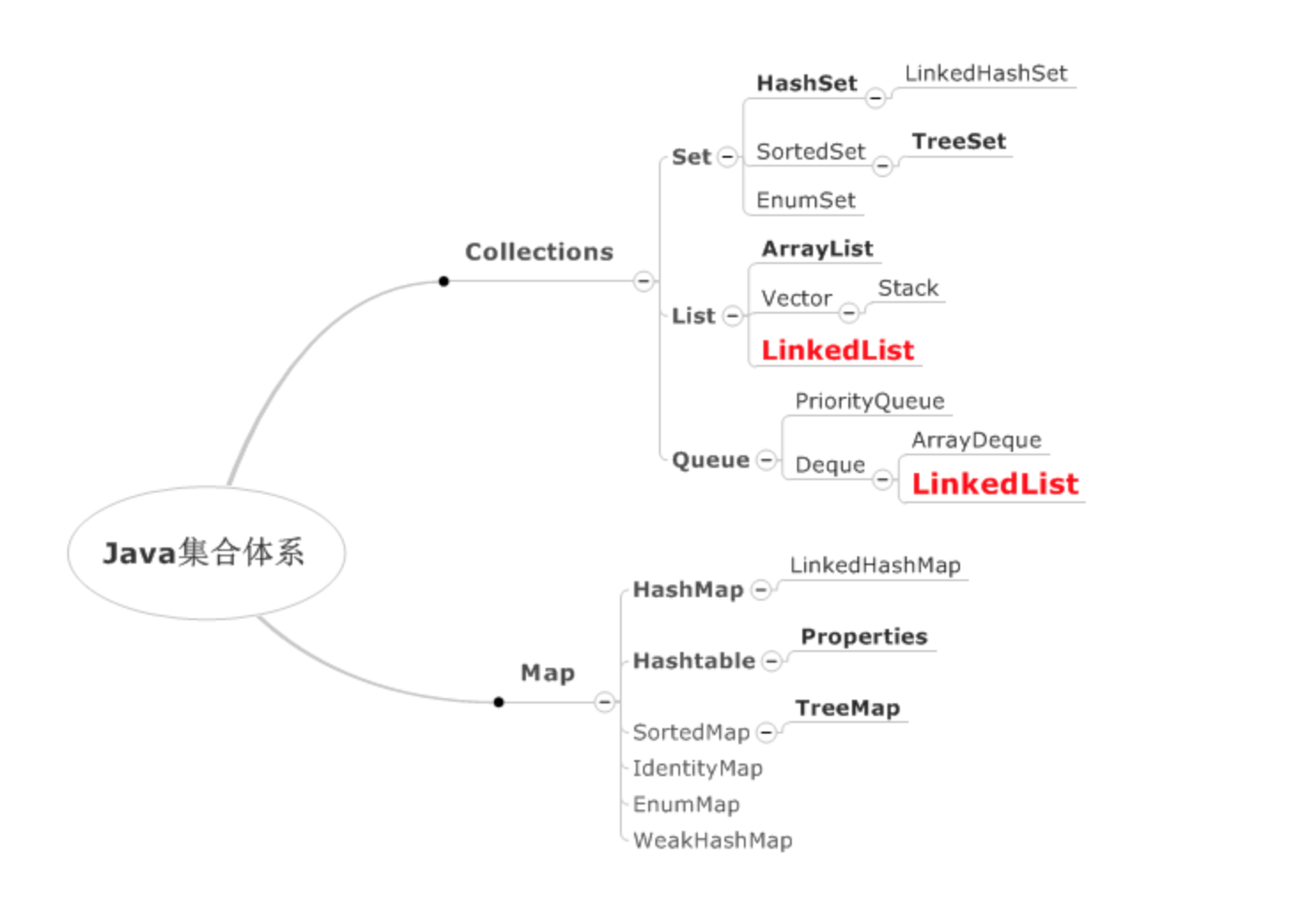
基本可以从名字知道集合的内部数据结构。
- 看后缀,有Set,List,Map后缀的集合,代表着该集合的基本结构,所以会具有以上所说的特性。
- 看前缀,前缀往往代表着该数据结构的具体实现方式。一般有这几种:
- Hash或者Array,代表着以哈希(基本)数组实现的数据结构。
- Linked,代表着集合内各个数据之间存在链表关系。
- Tree或者Sorted,代表着内部使用红黑树实现了排序。(需要提供Comparator或者实现Comparable)
下面大略说下每个集合的数据结构,懒得贴源码了。
1.1 List
最常用的List就是ArrayList和LinkedList了,在此不讨论并发的List集合。
讨论下底层源码对它们的具体实现。
1.1.1 ArrayList
使用JAVA的基本数组实现的动态数组集合,源码底层维护着List的容量与实际长度。
因为使用的基本数组,不像哈希数组一样需要考虑哈希碰撞问题,因此负载因子默认为1。当List数组容量不够时才进行扩容,扩容的倍数为1.5倍。
通过Arrays.copyOf方法,返回复制的新数组。Arrays.copyOf底层调用的System.arraycopy方法。而在ArrayList初始化时,如果不指定初始数组长度,在JDK1.6之后默认初始长度为0,在JDK1.6之前则默认为10。在JDK1.6后,ArrayList在第一次扩容时,如果扩容长度不足10,则会直接扩容到10。
具体集合怎么使用就不废话了。
1.1.2 LinkedList
这是一个双向链表,其中节点用的是LinkedList的内部类。和数据结构中的链表差不多。可以用它实现栈和队列。
1.1.3 ArrayList与LinkedList比较
很明显,ArrayList是某种程度上的哈希表,适合随机读,但是不适合在集合中间插入和删除(会造成后续数据的位移)。
而LinkedList适合在头尾部插入删除,不适合随机读。
值得一提的是ArrayList随机读的时间复杂度是O(1),LinkedList是O(n)。而ArrayList在中间插入和删除的时间复杂度是O(n),LinekdList在中间插入删除时间复杂度也是O(n)
可以明显看出来ArrayList在插入删除上和LinkedList理论上所用的时间是一个级别的,但是ArrayList慢于LinkedList是因为在修改集合后需要进行其他数组数据的移动,而LinkedList则是查找节点花费了O(n),不需要额外移动数据,所以在同样数据量时,LinkedList进行数据修改优于ArrayList。
1.2 Map
最常用的Map就是HashMap和TreeMap。
1.2.1 HashMap
HashMap是底层用哈希数组实现的Map。HashMap就是一个个Entry(Key-Value键值对)存储在一个哈希数组上(Entry是HashMap的内部类)。
哈希数组的使用不可避免的需要考虑哈希碰撞问题,常用的解决方案有:
- 拉链法
- 再哈希法
- 开放地址法
- 建立公共溢出区。
在JDK里,使用的就是拉链法解决的哈希碰撞问题,因此每个哈希数组上的数组元素(又被称为桶――bucket),都是一个链表的表头。这样基本保证了HashMap的平均查找时间是O(1)。
HashMap的负载因子为0.75
但是当出现频繁哈希碰撞时,会导致某个链表过长进而导致了查找时间会趋近于O(n)。对此JDK原本的解决方案是设置负载因子为0.75。当哈希表总负载量达到0.75时,就会进行扩容,扩容为原本的2倍。这样当数据平均下来后,不太容易出现过长的链表(因为扩容会分解链表重新放入桶中)。
但是这并没有解决特殊情况下查找效率的问题,只是让这种特殊情况更难以出现了。
JDK1.8中 HashMap出现了红黑树
因此在JDK1.8中又做出了改进,当某个桶中的链表的长度大于8时。链表会重构成一个红黑树。这样保证了HashMap的最坏时间复杂度也仅仅是O(logn)。同时负载因子引起的扩容也保证了红黑树的重构不会频繁发生,不会因为频繁建树导致过多的性能开销。
HashMap的初始化与扩容
另外值得一说的就是HashMap在不知道初始长度进行初始化时,JDK1.6前默认长度为16,JDK1.6后默认长度为0。基本在JDK1.6中,需要初始化底层容器的集合都做出了这种优化。不会提前构造底层容器造成开销,会等到使用时才进行底层的初始化。
而HashMap默认长度设置为16,并且每次扩容都是2倍。这是为了方便底层的哈希数组进行取模时的运算,可以把取模的除法运算改写成位移运算,提升性能。
并且在JDK1.8中,HashMap关于取模运算还做了另一个优化。在JDK1.8之前,每次哈希数组扩容时,链表里的数据都会再次进行哈希运算。而在JDK1.8后,不需要再进行运算了,只需要在每个桶中选择一半数据往后移动oldLength位就行(oldLength是集合在扩容前的容量)。
1.2.2 TreeMap
而另一个常用的Map――TreeMap,底层就是用JAVA写了一个红黑树,感觉没什么好说的。有兴趣的可以回去翻翻数据结构的书。
1.2.3 LinkedHashMap
HashMap的每个Node还会以插入顺序相互关联成为双向链表。
1.3 Set
Set主要是SortedSet和HashSet。打开源码一看,分别new了一个TreeMap和HashMap,然后把数据存在了Key里。嗯,这就是Set的底层实现了。
原文链接:https://www.cnblogs.com/taojinxuan/p/11133287.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- 国外程序员整理的Java资源大全(全部是干货) 2020-06-12
- 2020年深圳中国平安各部门Java中级面试真题合集(附答案) 2020-06-11
- 2020年java就业前景 2020-06-11
- 04.Java基础语法 2020-06-11
- Java--反射(框架设计的灵魂)案例 2020-06-11
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
