
HashMap与ConcurrentHashMap
2018-07-09 13:28:52来源:博客园 阅读 ()

HashMap
(1)初始化方法
HashMap的实现方式是:数组+链表 的形式。

在HashMap中有两个参数会影响HashMap的性能:初始容量/加载因子
初始容量:Hash表中桶的数量
加载因子:是Hash表在自动增加之前可以达到多满的一个尺度。
通过计算key的hash值和数组长度值进行取模确定该key在数组中的索引。
//初始容量,默认16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//加载因子,默认0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
这两个参数的作用是:当Hash表中的条目数量超过了加载因子与当前容量的乘积,将会调用resize()进行扩容,将容量翻倍。
这两个参数在初始化HashMap的时候可以进行设置:可以单独指定初始容量,也可以同时设置

(3)HashMap的线程不安全原因一:死循环
原因在于HashMap在多线程情况下,执行resize()进行扩容时容易造成死循环。
扩容思路为它要创建一个大小为原来两倍的数组,保证新的容量仍为2的N次方,从而保证上述寻址方式仍然适用。扩容后将原来的数组从新插入到新的数组中。这个过程称为reHash。
【单线程下的reHash】
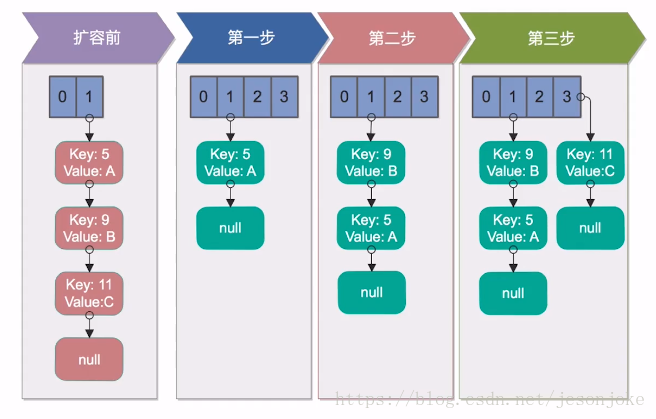
- 扩容前:我们的HashMap初始容量为2,加载因子为1,需要向其中存入3个key,分别为5、9、11,放入第三个元素11的时候就涉及到了扩容。
- 第一步:先创建一个二倍大小的数组,接下来把原来数组中的元素reHash到新的数组中,5插入新的数组,没有问题。
- 第二步:将9插入到新的数组中,经过Hash计算,插入到5的后面。
- 第三步:将11经过Hash插入到index为3的数组节点中。
单线程reHash完全没有问题。
【多线程下的reHash】

我们假设有两个线程同时需要执行resize操作,我们原来的桶数量为2,记录数为3,需要resize桶到4,原来的记录分别为:[3,A],[7,B],[5,C],在原来的map里面,我们发现这三个entry都落到了第二个桶里面。
假设线程thread1执行到了transfer方法的Entry next = e.next这一句,然后时间片用完了,此时的e = [3,A], next = [7,B]。线程thread2被调度执行并且顺利完成了resize操作,需要注意的是,此时的[7,B]的next为[3,A]。此时线程thread1重新被调度运行,此时的thread1持有的引用是已经被thread2 resize之后的结果。线程thread1首先将[3,A]迁移到新的数组上,然后再处理[7,B],而[7,B]被链接到了[3,A]的后面,处理完[7,B]之后,就需要处理[7,B]的next了啊,而通过thread2的resize之后,[7,B]的next变为了[3,A],此时,[3,A]和[7,B]形成了环形链表,在get的时候,如果get的key的桶索引和[3,A]和[7,B]一样,那么就会陷入死循环。
(4)HashMap的线程不安全原因二:fail-fast
如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast。
在每一次对HashMap进行修改的时候,都会变动类中的modCount域,即modCount变量的值。
ConcurrentHashMap
(1)结构 [Java7与Java8不同]

- Java7里面的ConcurrentHashMap的底层结构仍然是数组和链表,与HashMap不同的是ConcurrentHashMap的最外层不是一个大的数组,而是一个Segment数组。每个Segment包含一个与HashMap结构差不多的链表数组。
- 当我们读取某个Key的时候它先取出key的Hash值,并将Hash值得高sshift位与Segment的个数取模,决定key属于哪个Segment。接着像HashMap一样操作Segment。
- 为了保证不同的Hash值保存到不同的Segment中,ConcurrentHashMap对Hash值也做了专门的优化。
-
Segment继承自J.U.C里的ReetrantLock,所以可以很方便的对Segment进行上锁。即分段锁。理论上最大并发数是和segment的个数是想等的。

-
Java8为了进一步提高并发性,废弃了Java7中ConcurrentHashMap中分段锁的方案,并且不使用Segment,转为使用大的数组。同时为了提高Hash碰撞下的寻址做了性能优化。
- Java8在列表的长度超过了一定的值(默认8)时,将链表转为红黑树实现。寻址的复杂度从O(n)转换为Olog(n)。java8也是通过计算key的hash值和数组长度值进行取模确定该key在数组中的索引。但是java8引入红黑树,即使hash冲突比较高,寻址效率也会是比较高的。
对比
- HashMap非线程安全、ConcurrentHashMap线程安全
- HashMap允许Key与Value为空,ConcurrentHashMap不允许
- HashMap不允许通过迭代器遍历的同时修改,ConcurrentHashMap允许。并且更新可见
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- HashMap:源代码(构造方法、put、resize、get、remove、rep 2020-06-04
- HashMap1.7和1.8,红黑树原理! 2020-06-03
- JDK1.7和1.8的HashMap对比详解 2020-06-02
- equals 和 hashCode 到底有什么联系? 2020-05-25
- HashMap理解 2020-05-24
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
