
Java�Զ��ڴ��������ѧϰ�������������������롭
2018-06-27 10:04:30��Դ��δ֪ �Ķ� ()

��ע���������ԡ���������Java������ڶ��桷�����ο�
ͼƬ���ԣ�http://csdn.net/WSYW126
�����ռ������ڴ�������
����
GCҪ���3���£�
- ��Щ�ڴ���Ҫ���գ�
- ʲôʱ����գ�
- ��λ��գ�
Java�ڴ�����ʱ����ĸ����֣����г���������������ջ�����ط���ջ3���������̶߳��������̶߳���ջ�е�ջ֡���ŷ����Ľ�����˳����������ɵ�ִ������ջ�ͳ�ջ������ÿһ��ջ֡�з�������ڴ������������ṹȷ������ʱ����֪�ģ�����⼸��������ڴ����ͻ��ն��߱�ȷ���ԣ����⼸�������ھͲ���Ҫ����ǻ��յ����⣬��Ϊ�������������߳̽������ڴ���Ȼ�����Ż����ˡ�
��Java�Ѻͷ�������һ����һ���ӿ��еĶ��ʵ������Ҫ���ڴ���ܲ�һ����һ�������еĶ��ʵ������Ҫ���ڴ���ܲ�һ����һ�������еĶ����֧��Ҫ���ڴ�Ҳ���ܲ�һ����ֻ���ڳ����������ڼ�ʱ����֪���ᴴ����Щ�����ⲿ���ڴ�ķ���ͻ����Ƕ�̬�ģ������ռ�������ע�����ⲿ�ֵ��ڴ档
����������
���ü����㷨
����������һ�����ü�������ÿ����һ���ط��������ĵط���������ֵ+1��������ʧЧ��������ֵ�ͼ�1;�κ�ʱ�������Ϊ0������Ͳ������ٱ������ˡ�
�����ѽ������֮���ѭ�����õ����⡣
�ɴ��Է����㷨
���������������ԣ�Java��C#���ж�ʹ�ÿɴ��Է�����Reachability Analysis�����ж������Ƿ���ġ�
ͨ��һϵ�еij�Ϊ��GC Roots���Ķ�����Ϊ��ʼ�㣬����Щ�ڵ㿪ʼ�����������������߹���·����Ϊ��������Reference Chain��,��һ������GC Rootsû���κ�����������ʱ����֤���˶����Dz����õġ�
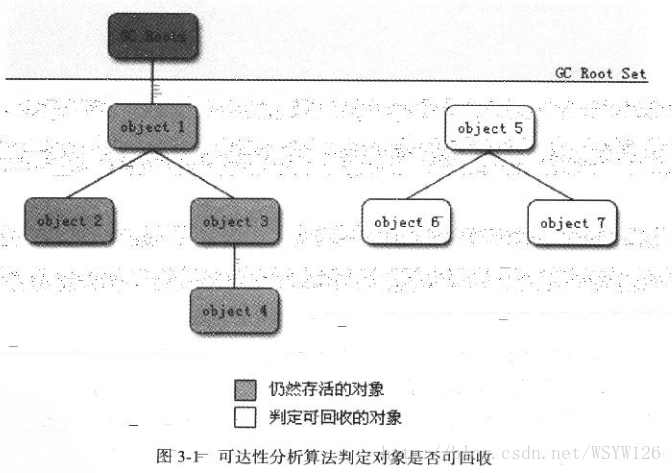
object5 6 7 ����GC Roots�Dz��ɴ�ģ����Իᱻ�ж�Ϊ���ն���
��Java�����У�������ΪGc Roots�Ķ���������漸�֣�
- �����ջ��ջ֡�еı��ر������������õĶ���
- ���������ྲ̬�������õĶ���
- �������г������õĶ���
- ���ط���ջ��JNI����һ��˵��Native���������õĶ���
��̸����
��JDK 1.2 ֮��Java�����õĸ�����������䣬�����÷�Ϊǿ���ã�Strong Reference���������ã�Soft Reference���������ã�Weak Reference���������ã�Phantom Reference��4�֣���4������ǿ������������
- ǿ���þ���ָ�ڳ������֮���ձ���ڵģ����ơ�Object obj = new Object()����������ã�ֻҪǿ���û����ڣ������ռ�����Զ������յ������õĶ���
- ����������������һЩ�����õ����DZ���Ķ����������ù����ŵĶ�����ϵͳ��Ҫ�����ڴ�����쳣֮ǰ���������Щ�����н����շ�Χ֮�н��еڶ��λ��ա������λ��ջ�û���㹻���ڴ棬�Ż��׳��ڴ�����쳣����JDK 1.2֮���ṩ��SoftReference����ʵ�������á�
- ������Ҳ�����������DZ������ģ���������ǿ�ȱ������ø���һЩ���������ù����Ķ���ֻ�����浽��һ�������ռ�����֮ǰ���������ռ�������ʱ�����۵�ǰ�ڴ��Ƿ��㹻��������յ�ֻ�������ù����Ķ�����JDK 1.2֮���ṩ��WeakReference����ʵ�������á�
- ������Ҳ��Ϊ�������û���Ӱ���ã�����������һ�����ù�ϵ��һ�������Ƿ��������õĴ��ڣ���ȫ�����������ʱ�乹��Ӱ�죬Ҳ��ͨ����������ȡ��һ������ʵ����Ϊһ���������������ù�����ΨһĿ�ľ���������������ռ�������ʱ�յ�һ��ϵͳ֪ͨ����JDK 1.2֮���ṩ��PhantomReference����ʵ�������á�
���滹��������
��ʹ�ڿɴ��Է����㷨�в��ɴ�Ķ���Ҳ�����ǡ��������ɡ��ģ���ʱ��������ʱ���ڡ����̡��Σ�Ҫ��������һ����������������Ҫ�������α�ǹ��̣���������ڽ��пɴ��Է�������û����GC Roots�����ӵ����������������ᱻ��һ�α�Dz��ҽ���һ��ɸѡ��ɸѡ�������Ǵ˶����Ƿ��б�Ҫִ��finalize()������������û�и���finalize()����������finalize()�����Ѿ�����������ù�����������������������Ϊ��û�б�Ҫִ�С���
�����������ж�Ϊ�б�Ҫִ��finalize()��������ô������������һ������F-Queue�Ķ���֮�У������Ժ���һ����������Զ������ġ������ȼ���Finalizer�߳�ȥִ������������ν�ġ�ִ�С���ָ������ᴥ�������������������ŵ��ȴ������н�������������ԭ���ǣ����һ��������finalize()������ִ�л��������߷�������ѭ���������˵�����������ܿ��ܻᵼ��F-Queue�����������������ô��ڵȴ����������������ڴ����ϵͳ������finalize()�����Ƕ��������������˵����һ�λ��ᣬ�Ժ�GC����F-Queue�еĶ�����еڶ���С��ģ�ı�ǣ��������Ҫ��finalize()�гɹ������Լ�����ֻҪ�������������ϵ��κ�һ���������������ɣ�Ʃ����Լ���this�ؼ��֣���ֵ��ij����������߶���ij�Ա���������ڵڶ��α��ʱ�������Ƴ������������ա��ļ��ϣ����������ʱ��û�����ѣ��ǻ�����������ı������ˡ��������ӿ��Կ���finalize()��ִ�У���������Ȼ���Դ�
package cc.wsyw126.java.garbageCollection;
public class FinalizeEscapeGC {
public static FinalizeEscapeGC SAVE_HOOK = null;
public void isAlive() {
System.out.println("yes, I am still alive :)");
}
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize method executed!");
SAVE_HOOK = this;
}
public static void main(String[] args) throws InterruptedException {
SAVE_HOOK = new FinalizeEscapeGC();
SAVE_HOOK = null;
System.gc();
//��Ϊfinalize�������ȼ��ܵ�,������ͣ0.5��ȴ���
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no, i am dead :(");
}
//����������һ�� ��������Ծ�ʧ��
SAVE_HOOK = null;
System.gc();
//��Ϊfinalize�������ȼ��ܵ�,������ͣ0.5��ȴ���
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no, i am dead :(");
}
}
}
������
finalize method executed!
yes, I am still alive :)
no, i am dead :(
һ���Ĵ��룬һ�����ѣ�һ��ʧ�ܡ���Ϊ�����finalize()ֻ�ܱ�ϵͳִ��һ�Ρ�
�����Ҿ�������ʹ��������Ϊ������C/C++�е���������������Java�յ���ʱΪ��ʹC/C++����Ա������������������һ����Э���������д��۸߰�����ȷ���Դ�����֤��������ĵ���˳��
���շ�����
�ڶ��У����������������У�����Ӧ�ý���һ�������ռ�һ����Ի���70%~95%�Ŀռ䣬�����ô��������ռ�Ч��Զ���ڴˡ�
���ô�������������Ҫ�������������ݣ��������������õ��ࡣ�������������жϱȽϼ����ǡ����õ��ࡱ���жϸ���һЩ����Ҫ��������3��������
- �������е�ʵ�����Ѿ������գ�Ҳ����Java���в����ڸ�����κ�ʵ����
- ���ظ����ClassLoader�Ѿ������ա�
- �����Ӧ��java.lang.Class����û�����κεط������ã������κεط�ͨ��������ʸ���ķ�����
�Ƿ������л��գ�HotSpot������ṩ��-Xnoclassgc�������п��ƣ�������ʹ��-verbose:class�Լ�-XX:+TraceClassLoading, -XX:+TraceClassUnLoading�鿴����Ӱ���ж����Ϣ������-verbose:class��-XX:+TraceClassLoading������Product����������ʹ�ã�-XX:+TraceClassUnLoading������ҪFastDebug��������֧�֡�
�ڴ���ʹ�÷��䡢��̬������Cglib��ByteCode��ܡ���̬����JSP�Լ�OSGI����Ƶ���Զ���ClassLoader�ij�������Ҫ������߱���ж�صĹ��ܣ��Ա�֤���ô����������
�����ռ��㷨
���-����㷨
��ͬ��������һ�����㷨��Ϊ����ǡ��͡�����������Σ����ȱ�dz�������Ҫ���յĶ����ڱ����ɺ�ͳһ�������б���ǵĶ���������Ҫ������������һ����Ч�����⣬��Ǻ�����������̵�Ч�ʶ����ߣ���һ���ǿռ����⣬������֮�������������������ڴ���Ƭ���ռ���Ƭ̫����ܻᵼ���Ժ��ڳ������й�������Ҫ����ϴ����ʱ�����ҵ��㹻�������ڴ�����ò���ǰ������һ�������ռ���������ǡ�����㷨��ִ�й�������ͼ��ʾ��

�����㷨
Ϊ�˽��Ч�����⣬һ�ֳ�Ϊ�����ơ���Copying�����ռ��㷨�����ˣ����������ڴ水��������Ϊ��С��ȵ����飬ÿ��ֻʹ�����е�һ�顣����һ����ڴ������ˣ��ͽ�������ŵĶ����Ƶ�����һ�����棬Ȼ���ٰ���ʹ�ù����ڴ�ռ�һ��������������ʹ��ÿ�ζ��Ƕ��������������ڴ���գ��ڴ����ʱҲ�Ͳ��ÿ����ڴ���Ƭ�ȸ��������ֻҪ�ƶ��Ѷ�ָ�룬��˳������ڴ漴�ɣ�ʵ�ּ����и�Ч��ֻ�������㷨�Ĵ����ǽ��ڴ���СΪ��ԭ����һ�룬δ��̫����һ�㡣�����㷨��ִ�й�������ͼ��ʾ��

���ڵ���ҵ����������������ռ��㷨��������������IBM��˾��ר���о��������������еĶ���98%�ǡ�����Ϧ�����ģ����Բ�����Ҫ����1:1�ı����������ڴ�ռ䣬���ǽ��ڴ��Ϊһ��ϴ��Eden�ռ�������С��Survivor�ռ䣬ÿ��ʹ��Eden������һ��Survivor��������ʱ����Eden��Survivor�л�����ŵĶ���һ���Եظ��Ƶ�����һ��Survivor�ռ��ϣ����������Eden�ղ��ù���Survivor�ռ䡣HotSpot�����Ĭ��Eden��Survivor�Ĵ�С������8:1��Ҳ����ÿ���������п����ڴ�ռ�Ϊ����������������90%��80%+10%����ֻ��10%���ڴ�ᱻ���˷ѡ�����Ȼ��98%�Ķ���ɻ���ֻ��һ�㳡���µ����ݣ�����û�а취��֤ÿ�λ��ն�ֻ�в�����10%�Ķ������Survivor�ռ䲻����ʱ����Ҫ���������ڴ棨����ָ����������з��䵣����Handle Promotion��
���䵣��:�������һ��Survivor�ռ�û���㹻�ռ�����һ���������ռ������Ĵ�����ʱ����Щ����ֱ��ͨ�����䵣�����ƽ����������
���-�����㷨
��ǹ�����Ȼ�롰���-������㷨һ�������������費��ֱ�ӶԿɻ��ն���������������������д��Ķ�����һ���ƶ���Ȼ��ֱ���������˱߽�������ڴ棬�����-�������㷨��ʾ��ͼ��ͼ��ʾ��

�ִ��ռ��㷨
���ݶ��������ڵIJ�ͬ���ڴ��Ϊ���顣һ���Java�ѷ�Ϊ������������������ݸ���������ص��������ʵ��ռ��㷨�����������У�ÿ�������ռ�ʱ�д���������ȥ��ֻ������������ѡ�ø����㷨����������������ʸߣ�ʹ�ñ��������߱�������㷨��
HotSpot���㷨ʵ��
ö�ٸ��ڵ�
�ӿɴ��Է����д�GC Roots�ڵ����������������Ϊ��������ΪGC Roots�Ľڵ���Ҫ��ȫ���Ե����ã����糣�����ྲ̬���ԣ���ִ�������ģ�����֡ջ�еı��ر��������У����ںܶ�Ӧ�ý������������������ף����Ҫ����������������ã���ô��Ȼ�����ĺܶ�ʱ�䡣
���⣬�ɴ��Է�����ִ��ʱ������л�������GCͣ���ϣ���Ϊ�����������������һ����ȷ��һ���ԵĿ����н��ШC���һ���ԡ�����˼��ָ�����������ڼ�����ִ��ϵͳ��������������ij��ʱ����ϣ������Գ��ַ��������ж������ù�ϵ���ڲ��ϱ仯��������õ㲻����Ļ��������ȷ�Ծ����õ���֤������ǵ���GC����ʱ����ͣ������Javaִ���̣߳�Sun����������Ϊ��Stop The World����������һ����Ҫԭ��ʹ���ںųƣ����������ᷢ��ͣ�ٵ�CMS�ռ����У�ö�ٸ��ڵ�Ҳ�DZ���Ҫͣ�ٵġ�
����Ŀǰ������Java�����ʹ�õĶ���ȷʽGC�����Ե�ִ��ϵͳͣ������������Ҫһ����©�ؼ��������ִ�������ĺ�ȫ�ֵ�����λ�ã������Ӧ�����а취ֱ�ӵ�֪��Щ�ط�����Ŷ�������á���HotSpot��ʵ���У���ʹ��һ���ΪOopMap�����ݽṹ���ﵽ���Ŀ�ĵģ����������ɵ�ʱ��HotSpot�ͰѶ�����ʲôƫ��������ʲô���͵����ݼ����������JIT��������У�Ҳ�����ض���λ�ü�¼��ջ�ͼĴ�������Щλ�������á�������GC��ɨ��ʱ�Ϳ���ֱ�ӵ�֪��Щ��Ϣ�ˡ�
��ȫ��
��OopMap��Э���£�HotSpot���Կ�����ȷ�����GC Rootsö�٣���һ������ʵ��������֮���������ܵ������ù�ϵ�仯������˵OopMap���ݱ仯��ָ��dz��࣬���Ϊÿһ��ָ����ɶ�Ӧ��OopMap���ǽ�����Ҫ�����Ķ���ռ䣬����GC�Ŀռ�ɱ������úܸߡ�
ʵ���ϣ�HotSpotҲ��ȷû��Ϊÿ��ָ�����OopMap��ǰ���Ѿ��ᵽ��ֻ���ڡ��ض���λ�á���¼����Щ��Ϣ����Щλ�ó�Ϊ��ȫ�㣨Safepoint����������ִ��ʱ���������еط�����ͣ��������ʼGC��ֻ���ڵ��ﰲȫ��ʱ������ͣ��Safepoint��ѡ��������̫����������GC�ȴ�ʱ��̫����Ҳ���ܹ���Ƶ�������ڹ�����������ʱ���ɡ����ԣ���ȫ���ѡ�����������Գ����Ƿ�����ó���ʱ��ִ�е�������Ϊ������ѡ���ĨC��Ϊÿ��ָ��ִ�е�ʱ�䶼�dz����ݣ�����̫������Ϊָ��������̫�����ԭ�������ʱ�����У�����ʱ��ִ�С�����������������ָ�����и��ã����緽�����á�ѭ����ת���쳣��ת�ȣ����Ծ�����Щ���ܵ�ָ��Ż����Safepoint��
����Safepoint����һ����Ҫ���ǵ������������GC����ʱ�������̣߳����ﲻ����ִ��JNI���õ��̣߳������ܡ�������İ�ȫ������ͣ�����������������ַ����ɹ�ѡ��
- ����ʽ�жϣ�Preemptive Suspension��
- ����ʽ�жϣ�Voluntary Suspension��
��������ʽ�жϲ���Ҫ�̵߳�ִ�д�������ȥ��ϣ���GC����ʱ�����Ȱ������߳�ȫ���жϣ�����������߳��жϵĵط����ڰ�ȫ���ϣ��ͻָ��̣߳��������ܡ�����ȫ���ϡ����ڼ���û�������ʵ�ֲ�������ʽ�ж�����ͣ�̴߳Ӷ���ӦGC�¼���
������ʽ�жϵ�˼���ǵ�GC��Ҫ�ж��̵߳�ʱ��ֱ�Ӷ��̲߳���������������һ����־�������߳�ִ��ʱ����ȥ��ѯ�����־�������жϱ�־Ϊ��ʱ���Լ��жϹ�����ѯ��־�ĵط��Ͱ�ȫ�����غϵģ������ټ��ϴ���������Ҫ�����ڴ�ĵط���
��ȫ����
ʹ��Safepoint�ƺ��Ѿ������ؽ������ν���GC�����⣬��ʵ�����ȴ����һ����Safepoint���Ʊ�֤�˳���ִ��ʱ���ڲ�̫����ʱ���ھͻ������ɽ���GC��Safepoint�����ǣ�����͡���ִ�С���ʱ���أ���ν�ij���ִ�о���û�з���CPUʱ�䣬���͵����Ӿ����̴߳���Sleep״̬����Blocked״̬����ʱ���߳�����ӦJVM���ж������ߡ�����ȫ�ĵط�ȥ�жϹ���JVMҲ��Ȼ��̫���ܵȴ��߳����±�����CPUʱ�䡣�����������������Ҫ��ȫ����Safe Region���������
��ȫ������ָ��һ�δ���Ƭ��֮�У����ù�ϵ���ᷢ���仯������������е�����ط���ʼGC���ǰ�ȫ�ġ�����Ҳ����Safe Region�����DZ���չ�˵�Safepoint��
���߳�ִ�е�Safe Region�еĴ���ʱ�����ȱ�ʶ�Լ��Ѿ�������Safe Region���������������ʱ����JVMҪ����GCʱ���Ͳ��ùܱ�ʶ�Լ�ΪSafe Region״̬���߳��ˡ����߳�Ҫ�뿪Safe Regionʱ����Ҫ���ϵͳ�Ƿ��Ѿ�����˸��ڵ�ö�٣�����������GC���̣����������ˣ����߳̾ͼ���ִ�У��������ͱ�������ȴ�ֱ���յ�����ȫ�뿪Safe Region���ź�Ϊֹ��
�����ռ���
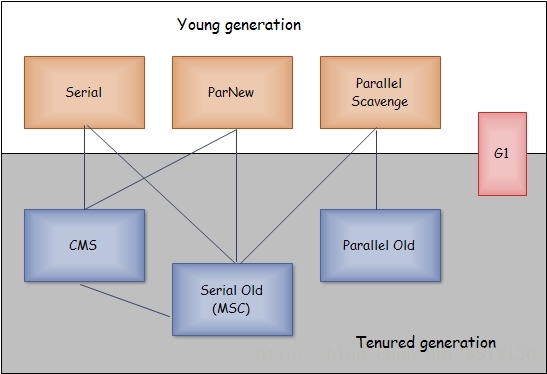
Serial Collecor
Serial�ռ����ǵ��߳��ռ������Ƿִ��ռ����������������ռ�ʱ��������ͣ�������еĹ����̣߳�ֱ�����ռ�������
- �����������̸߳����ռ��㷨��
- ����������̱߳�������㷨��
Serialһ���ڵ��˵Ļ�����ʹ�ã���Java 5�Ƿ����JVM��Ĭ���ռ���������-XX:UseSerialGC����ʹ�á�
ParNew�ռ���
ParNew�ռ�����Serial�ռ�������Ҫ������
- ���������ռ���һ���ǵ��߳�һ���Ƕ��̡߳�
- ��������ռ���Serial�ռ�����һ���ġ�
ʵ������Serial�ռ����Ķ��̰߳汾��ӵ�пɿ��Ʋ������磺-XX:SurvivorRatio, -XX:PretenureSizeThreshold, -XX:HandlePromotionFailure�ȣ����ռ��㷨��ͣ�٣������������ղ��Զ���Serial�ռ�����ȫһ����
ParNew�ռ���������������serverģʽ�µ����������ѡ���������ռ�����һ����Ҫ��ԭ���ǣ�ֻ��ParNew��Serial�ռ����ܺ�CMS�ռ�����ͬ����������JDK1.4�д��ڵ��������ռ���Parallel Scavenge��Ϲ�����������JDK1.5��ʹ��CMS���ռ��������ʱ��������ֻ��ѡ��ParNew��Serial��
ParNew�ռ�����ʹ��-XX:+UseConcMarkSweepGCѡ���Ĭ���������ռ�����Ҳ������-XX:+UseParNewGCѡ����ǿ��ָ������
ParNew�ռ����ڵ�CPU�����в���SerialЧ���ã��������ܸ������CPUҲ��һ���ܵĹ���������CPU���������ӣ����ܻ������ӡ�Ĭ�Ͽ������ռ��߳�����CPU������ͬ����CPU�����ܶ������£�����ʹ��-XX:ParallelGCThreads�����������߳�����
Parallel����: �������ռ��̲߳��й��������û��߳�����ȴ�
Concurrent����:�û��̺߳������ռ�ͬʱ���С�
Parallel Scavenge�ռ���
ͬParNewһ����ʹ�ø����㷨�����������ж��߳��ռ�����
Parallel Scavenge���ص������Ĺ�ע���������ռ�����ͬ��CMS���ռ����Ĺ�ע�㾡���ܵ����������ռ�ʱ�û��̵߳�ͣ��ʱ�䣬��Parallel Scavenge�ռ�����Ŀ�����Ǵﵽһ���ɿ��Ƶ���������Throughput������ν����������CPU���������û�������CPU������ʱ��ı�ֵ��
����������ͣ��ʱ��̵IJ�����ȣ���Ҫǿ�����������ɣ�������ǿ���û��������顣
Parallel Scavenge�ṩ��������������������ͣ��ʱ�䣺-XX:MaxGCPauseMillis��-XX:GCTimeRatio
- MaxGCPauseMillis������ֵ��һ��������ĺ��������ռ�����������֤�ڴ���ջ��ѵ�ʱ�䲻�����趨ֵ��GCͣ��ʱ����С�����������������������ռ�����ȡ�ģ�Ҳ����Ҫʹͣ��ʱ����̣��������յ�Ƶ�ʻ����ӡ�
- GCTimeRatio��ֵ��һ������0С��100��������Ҳ���������ռ�ʱ��ռ��ʱ��ı��ʡ���Ϊ19�����������GCʱ���ռ��ʱ���5%��1/��1+19������Ĭ��99.
Parallel Scavenge�ռ���Ҳ����Ϊ�����������ռ�����
����һ�������� -XX:+UseAdaptiveSizePolicy���Ǹ����ز���������Զ�����Eden/Survivor������������������䣬��������С�ȡ��������Ҳ��Parallel Scavenge��ParNew����Ҫ����
Serial Old�ռ���
��Serial��������汾��ͬ���ǵ��߳��ռ�����ʹ�ñ��-�����㷨����Ҫ��clientģʽ�µ������ʹ��
������;��
- ��JDK1.5��֮ǰ�İ汾����Parallel Scavenge����ʹ�á�
- ��ΪCMS�ռ����ĺ�Ԥ�����ڲ����ռ�����Concurrent Mode Failureʱʹ�á�
Parallel Old�ռ���
��Parallel Scavenge�ռ�����������汾��ʹ�ö��̺߳ͱ��-�����㷨����JDK1.6�вſ�ʼʹ�á�����֮ǰ�İ汾�У�Parallel Scavengeֻ��ʹ��Serial Old��Ϊ������ռ����������������ȵ����˼·���ܱ��ܺõĹ᳹����Parallel Old�ռ������ֺ������ߵ������Ҫ���ڹ᳹����˼·��
CMS�ռ���
Concurrent Mark Sweep �Ի�ȡ��̻���ͣ��ʱ��ΪĿ����ռ������Ƚ������Ӧ�ó�����B/S�ܹ��ķ�������
���ڱ��-����㷨ʵ�֣����й��̷ֳ�4�����裺
- ��ʼ���(��Ҫstop the world)�����һ��GC Roots��ֱ�ӹ������Ķ����ٶȺܿ졣
- ������ǣ�����GC Roots Tracing�Ĺ��̡�
- ���±��(��Ҫstop the world)��Ϊ�������������ʱ�û��������ж������ı�DZ仯��ͣ��ʱ��ȳ�ʼ��dz���Զ�Ȳ�����Ƕ̡�
- �������
ȱ�㣺
- CMS�ռ�����CPU��Դ�dz����С��ڲ����Σ�����Ȼ���ᵼ���û��߳�ͣ�٣�������Ϊռ����һ����CPU��Դ������Ӧ�ó�����������������ͻή�͡�CMSĬ�������Ļ����߳���Ϊ(CPU����+3)/4��Ϊ�˽����һ�������һ������i-CMS,��Ŀǰ�����Ƽ�ʹ�á�
- CMS�ռ�������������������floating garbage��.���ܻ����concurrent mode failure������һ��full gc�IJ�������CMS�IJ��������Σ����ڳ��������У���������ϲ�������һ�������������ڱ�ǹ���֮��CMS���ڱ����ռ��д��������ǣ�ֻ��������һ��GC�ٴ���������������Ϊ����������ͬ������CMS GC���û��̻߳���Ҫ���У�������ҪԤ���㹻���ڴ�ռ乩�û��߳�ʹ�ã����CMS�ռ��������������ռ��������ȵ������������ȫ���������ٽ����ռ�����ҪԤ��һ���ֿռ��ṩ�����ռ�ʱ�ij�������ʹ�á�Ĭ�������£�CMS�ռ����������ʹ����68%�Ŀռ��ͻᱻ������ֵ������-XX:CMSInitiatingOccupancyFraction�����á�Ҫ��CMS�����ڼ�Ԥ�����ڴ������������Ҫ���ͻ����concurrent mode failure����ʱ��ͻ�����Serial Old�ռ�����Ϊ���ý���������������ռ���
- �ռ���Ƭ���ࣨ���-����㷨�ıˣ����ṩ-XX:+UseCMSCompactAtFullCollection������Ӧ������FULL GC���ٽ���һ����Ƭ�������̡�-XX:CMSFullGCsBeforeCompaction,���ٴβ�ѹ����full gc����һ�δ�ѹ���ġ�
G1�ռ���
G1. Garbage first,�����з��Σ�ʹ�ñ��-�����㷨����ȷ����ͣ�٣���������ȫ���������ռ���ǰ����ռ������е��ռ���Χ�������������������������G1������JAVA�ѻ���Ϊ�����С�̶��Ķ�����������Щ��������������ѻ��̶ȣ��ں�̨ά��һ�������б���ÿ�����������ռ�ʱ������Ȼ���������������
����GC��־
[GC [PSYoungGen: 8987K->1016K(9216K)] 9984K->5056K(19456K), 0.0569611 secs] [Times: user=0.03 sys=0.02, real=0.06 secs]
[GC [PSYoungGen: 8038K->1000K(9216K)] 12078K->10425K(19456K), 0.0709523 secs] [Times: user=0.05 sys=0.00, real=0.07 secs]
[Full GC [PSYoungGen: 1000K->0K(9216K)] [ParOldGen: 9425K->8418K(10240K)] 10425K->8418K(19456K) [PSPermGen: 9678K->9675K(21504K)], 0.3152834 secs] [Times: user=0.39 sys=0.00, real=0.32 secs]
[Full GC [PSYoungGen: 8192K->3583K(9216K)] [ParOldGen: 8418K->9508K(10240K)] 16610K->13092K(19456K) [PSPermGen: 9675K->9675K(22016K)], 0.1913859 secs] [Times: user=0.34 sys=0.00, real=0.19 secs]
[Full GC [PSYoungGen: 7716K->7702K(9216K)] [ParOldGen: 9508K->9508K(10240K)] 17224K->17210K(19456K) [PSPermGen: 9675K->9675K(21504K)], 0.2769775 secs] [Times: user=0.52 sys=0.00, real=0.28 secs]
[Full GC [PSYoungGen: 7702K->7702K(9216K)] [ParOldGen: 9508K->9409K(10240K)] 17210K->17111K(19456K) [PSPermGen: 9675K->9675K(21504K)], 0.2491993 secs] [Times: user=0.64 sys=0.00, real=0.25 secs]- ��[GC���͡�[full DC��˵��������������յ�ͣ�����͡�����ǵ���System.gc()�������������ռ�����ô������ʾ��[Full DC(System)��.
[DefNew��[Tenured��[Perm��ʾGC���������������ParNew�ռ�������������Ϊ��[ParNew��.�������Parallel Scavenge�ռ���������������������Ϊ��[PSYoungGen������������������ô�ͬ����[PSYoungGen: 8987K->1016K(9216K)] 9984K->5056K(19456K), 0.0569611 secs]�к�������ֺ����ǣ�GCǰ���ڴ�������ʹ������->GC����ڴ�������ʹ��������������������������������֮��ı�ʾ��GCǰJava���Ѿ�ʹ�õ����� -> GC��Java���Ѿ�ʹ�õ�������Java�������������������ʱ���Ǹ�����GC��ռ�õ�ʱ�䣬��λ���롣[Times: user=0.03 sys=0.02, real=0.06 secs]�����user��sys��real��Linux��time�����������ʱ�京��һ���ֱ�����û�̬���ĵ�CPUʱ�䣬�ں�̬���ĵ�CPUʱ��Ͳ����ӿ�ʼ��������������ǽ��ʱ�䡣
�����ռ��������ܽ�
| �Ρ����� | �衡���� |
|---|---|
| UseSerialGC | �����������Clientģʽ�µ�Ĭ��ֵ���˿��غ�ʹ��Serial + Serial Old���ռ�����Ͻ����ڴ���� |
| UseParNewGC | �˿��غ�ʹ��ParNew + Serial Old���ռ�����Ͻ����ڴ���� |
| UseConcMarkSweepGC | �˿��غ�ʹ��ParNew + CMS + Serial Old���ռ�����Ͻ����ڴ���ա�Serial Old�ռ�������ΪCMS�ռ�������Concurrent Mode Failureʧ�ܺ�ĺ��ռ���ʹ�� |
| UseParallelGC | �����������Serverģʽ�µ�Ĭ��ֵ���˿��غ�ʹ��Parallel Scavenge + Serial Old��PS MarkSweep�����ռ�����Ͻ����ڴ���� |
| UseParallelOldGC | �˿��غ�ʹ��Parallel Scavenge + Parallel Old���ռ�����Ͻ����ڴ���� |
| SurvivorRatio | ��������Eden������Survivor�����������ֵ��Ĭ��Ϊ8������Eden��Survivor=8��1 |
| PretenureSizeThreshold | ֱ�ӽ�����������Ķ����С�������������������������Ķ���ֱ������������� |
| MaxTenuringThreshold | ������������Ķ������䡣ÿ�������ڼ�ֹ�һ��Minor GC֮�����������1���������������ֵʱ�ͽ�������� |
| UseAdaptiveSizePolicy | ��̬����Java���и�������Ĵ�С�Լ���������������� |
| HandlePromotionFailure | �Ƿ��������䵣��ʧ�ܣ����������ʣ��ռ䲻����Ӧ��������������Eden��Survivor�������ж����ļ������ |
| ParallelGCThreads | ���ò���GCʱ�����ڴ���յ��߳��� |
| GCTimeRatio | GCʱ��ռ��ʱ��ı��ʣ�Ĭ��ֵΪ99��������1%��GCʱ�䡣����ʹ��Parallel Scavenge�ռ���ʱ��Ч |
| MaxGCPauseMillis | ����GC�����ͣ��ʱ�䡣����ʹ��Parallel Scavenge�ռ���ʱ��Ч |
| CMSInitiatingOccupancyFraction | ����CMS�ռ�����������ռ䱻ʹ�ö��ٺ������ռ���Ĭ��ֵΪ68%������ʹ��CMS�ռ���ʱ��Ч |
| UseCMSCompactAtFullCollection | ����CMS�ռ�������������ռ����Ƿ�Ҫ����һ���ڴ���Ƭ����������ʹ��CMS�ռ���ʱ��Ч |
| CMSFullGCsBeforeCompaction | ����CMS�ռ����ڽ������ɴ������ռ���������һ���ڴ���Ƭ����������ʹ��CMS�ռ���ʱ��Ч |
�ڴ��������ղ���
������ڴ���䣬�����������ڶ��Ϸ��䣨��Ҳ���ܾ���JIT�����ɢΪ�������Ͳ���ӵ�ջ�Ϸ��䣩��������Ҫ��������������Eden���ϣ���������˱����̷߳��仺�壬�����߳�������TLAB�Ϸ��䡣���������Ҳ���ܻ�ֱ�ӷ�����������У�����Ĺ����ǰٷ�֮�ٹ̶��ģ���ϸ��ȡ���ڵ�ǰʹ�õ�����һ�������ռ�����ϣ���������������ڴ���صIJ��������á�
���������ǽ��ὲ�⼸�����ձ���ڴ�������ͨ������ȥ��֤��Щ����������Ĵ����ڲ���ʱʹ��Clientģʽ��������У�û���ֹ�ָ���ռ�����ϣ����仰˵����֤������ʹ��Serial / Serial Old�ռ����£�ParNew / Serial Old�ռ�����ϵĹ���Ҳ����һ�£����ڴ����ͻ��յIJ��ԡ����߲��������Լ���Ŀ��ʹ�õ��ռ���дһЩ����ȥ��֤һ��ʹ�����������ռ������ڴ������ԡ�
����������Eden����
���������£�������������Eden���з��䡣��Eden��û���㹻�ռ���з���ʱ�������������һ��Minor GC��
������ṩ��-XX:+PrintGCDetails����ռ�����־����������������ڷ��������ռ���Ϊʱ��ӡ�ڴ������־�������ڽ����˳���ʱ�������ǰ���ڴ����������������ʵ��Ӧ���У��ڴ������־һ���Ǵ�ӡ���ļ���ͨ����־���߽��з�����������ʵ�����־�����ֱ࣬���Ķ����ܿ��ú������
��������testAllocation()�����У����Է���3��2MB��С��1��4MB��С�Ķ���������ʱͨ��-Xms20M�� -Xmx20M�� -Xmn10M��3������������Java�Ѵ�СΪ20MB��������չ������10MB�������������ʣ�µ�10MB������������-XX:SurvivorRatio=8��������������Eden����һ��Survivor���Ŀռ������8��1��������Ľ��Ҳ���������ؿ�����eden space 8192K��from space 1024K��to space 1024K������Ϣ���������ܿ��ÿռ�Ϊ9216KB��Eden��+1��Survivor��������������
ִ��testAllocation()�з���allocation4��������ʱ�ᷢ��һ��Minor GC�����GC�Ľ����������6651KB��Ϊ148KB�������ڴ�ռ������û�м��٣���Ϊallocation1��allocation2��allocation3���������Ǵ��ģ����������û���ҵ��ɻ��յĶ������GC������ԭ���Ǹ�allocation4�����ڴ��ʱ����Eden�Ѿ���ռ����6MB��ʣ��ռ��Ѳ����Է���allocation4�����4MB�ڴ棬��˷���Minor GC��GC�ڼ�������ַ������е�3��2MB��С�Ķ���ȫ��������Survivor�ռ䣨Survivor�ռ�ֻ��1MB��С��������ֻ��ͨ�����䵣��������ǰת�Ƶ������ȥ��
���GC������4MB��allocation4����˳��������Eden�У���˳���ִ����Ľ����Edenռ��4MB����allocation4ռ�ã���Survivor���У��������ռ��6MB����allocation1��allocation2��allocation3ռ�ã���ͨ��GC��־����֤ʵ��һ�㡣
ע�⣺
������GC��Minor GC����ָ�������������������ռ���������ΪJava������߱�����Ϧ������ԣ�����Minor GC�dz�Ƶ����һ������ٶ�Ҳ�ȽϿ졣
�����GC��Major GC / Full GC����ָ�������������GC��������Major GC���������������һ�ε�Minor GC�����Ǿ��Եģ���Parallel Scavenge�ռ������ռ����������ֱ�ӽ���Major GC�IJ���ѡ����̣���Major GC���ٶ�һ����Minor GC��10�����ϡ�
private static final int _1MB = 1024 * 1024;
/**
* VM������-verbose:gc -Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8
*/
public static void testAllocation() {
byte[] allocation1, allocation2, allocation3, allocation4;
allocation1 = new byte[2 * _1MB];
allocation2 = new byte[2 * _1MB];
allocation3 = new byte[2 * _1MB];
allocation4 = new byte[4 * _1MB]; // ����һ��Minor GC
}
������
[GC [DefNew: 6651K->148K(9216K), 0.0070106 secs] 6651K->6292K(19456K), 0.0070426 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap
def new generation total 9216K, used 4326K [0x029d0000, 0x033d0000, 0x033d0000)
eden space 8192K, 51% used [0x029d0000, 0x02de4828, 0x031d0000)
from space 1024K, 14% used [0x032d0000, 0x032f5370, 0x033d0000)
to space 1024K, 0% used [0x031d0000, 0x031d0000, 0x032d0000)
tenured generation total 10240K, used 6144K [0x033d0000, 0x03dd0000, 0x03dd0000)
the space 10240K, 60% used [0x033d0000, 0x039d0030, 0x039d0200, 0x03dd0000)
compacting perm gen total 12288K, used 2114K [0x03dd0000, 0x049d0000, 0x07dd0000)
the space 12288K, 17% used [0x03dd0000, 0x03fe0998, 0x03fe0a00, 0x049d0000)
No shared spaces configured.�����ֱ�ӽ��������
��ν�Ĵ������ָ����Ҫ���������ڴ�ռ��Java��������͵Ĵ����������ֺܳ����ַ����Լ����飨�����г��������е�byte[]������ǵ��͵Ĵ������������������ڴ������˵����һ������Ϣ����Java�������Թһ�䣬������һ���������ӻ�����Ϣ��������һȺ������Ϧ�𡱵ġ����������д�����ʱ��Ӧ�����⣩���������ִ�����������ڴ滹�в��ٿռ�ʱ����ǰ���������ռ��Ի�ȡ�㹻�������ռ��������á����ǡ�
������ṩ��һ��-XX:PretenureSizeThreshold������������������ֵ�Ķ���ֱ������������䡣��������Ŀ���DZ�����Eden��������Survivor��֮�䷢���������ڴ渴�ƣ���ϰһ�£����������ø����㷨�ռ��ڴ棩��
ִ����������е�testPretenureSizeThreshold()���������ǿ���Eden�ռ伸��û�б�ʹ�ã����������10MB�ռ䱻ʹ����40%��Ҳ����4MB��allocation����ֱ�Ӿͷ�����������У�������ΪPretenureSizeThreshold������Ϊ3MB������3145728���������������-Xmx֮��IJ���һ��ֱ��д3MB������˳���3MB�Ķ���ֱ������������з��䡣
ע�⡡PretenureSizeThreshold����ֻ��Serial��ParNew�����ռ�����Ч��Parallel Scavenge�ռ�������ʶ���������Parallel Scavenge�ռ���һ�㲢����Ҫ���á������������ʹ�ô˲����ij��ϣ����Կ���ParNew��CMS���ռ�����ϡ�
private static final int _1MB = 1024 * 1024;
/**
* VM������-verbose:gc -Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8
* -XX:PretenureSizeThreshold=3145728
*/
public static void testPretenureSizeThreshold() {
byte[] allocation;
allocation = new byte[4 * _1MB]; //ֱ�ӷ������������
}
������
Heap
def new generation total 9216K, used 671K [0x029d0000, 0x033d0000, 0x033d0000)
eden space 8192K, 8% used [0x029d0000, 0x02a77e98, 0x031d0000)
from space 1024K, 0% used [0x031d0000, 0x031d0000, 0x032d0000)
to space 1024K, 0% used [0x032d0000, 0x032d0000, 0x033d0000)
tenured generation total 10240K, used 4096K [0x033d0000, 0x03dd0000, 0x03dd0000)
the space 10240K, 40% used [0x033d0000, 0x037d0010, 0x037d0200, 0x03dd0000)
compacting perm gen total 12288K, used 2107K [0x03dd0000, 0x049d0000, 0x07dd0000)
the space 12288K, 17% used [0x03dd0000, 0x03fdefd0, 0x03fdf000, 0x049d0000)
No shared spaces configured.
���ڴ��Ķ����������
��Ȼ����������˷ִ��ռ���˼���������ڴ棬��ô�ڴ����ʱ�ͱ�����ʶ����Щ����Ӧ��������������Щ����Ӧ����������С�Ϊ��������㣬�������ÿ����������һ���������䣨Age�������������������Eden������������һ��Minor GC����Ȼ�������ܱ�Survivor���ɵĻ��������ƶ���Survivor�ռ��У����Ҷ���������Ϊ1��������Survivor����ÿ��������һ��Minor GC�����������1�꣬�������������ӵ�һ���̶ȣ�Ĭ��Ϊ15�꣩���ͽ��ᱻ������������С���������������������ֵ������ͨ������-XX:MaxTenuringThreshold���á�
���߿������Էֱ���-XX:MaxTenuringThreshold=1��-XX:MaxTenuringThreshold=15����������ִ����������е�testTenuringThreshold()�������˷����е�allocation1������Ҫ256KB�ڴ棬Survivor�ռ�������ɡ���MaxTenuringThreshold=1ʱ��allocation1�����ڵڶ���GC����ʱ�������������������ʹ�õ��ڴ�GC��dz��ɾ��ر��0KB����MaxTenuringThreshold=15ʱ���ڶ���GC������allocation1����������������Survivor�ռ䣬��ʱ��������Ȼ��404KB��ռ�á�
private static final int _1MB = 1024 * 1024;
/**
* VM������-verbose:gc -Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=1
* -XX:+PrintTenuringDistribution
*/
@SuppressWarnings("unused")
public static void testTenuringThreshold() {
byte[] allocation1, allocation2, allocation3;
allocation1 = new byte[_1MB / 4];
// ʲôʱ����������ȡ����XX:MaxTenuringThreshold����
allocation2 = new byte[4 * _1MB];
allocation3 = new byte[4 * _1MB];
allocation3 = null;
allocation3 = new byte[4 * _1MB];
}
��MaxTenuringThreshold=1���������еĽ����
[GC [DefNew
Desired Survivor size 524288 bytes, new threshold 1 (max 1)
- age 1: 414664 bytes, 414664 total
: 4859K->404K(9216K), 0.0065012 secs] 4859K->4500K(19456K), 0.0065283 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
[GC [DefNew
Desired Survivor size 524288 bytes, new threshold 1 (max 1)
: 4500K->0K(9216K), 0.0009253 secs] 8596K->4500K(19456K), 0.0009458 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap
def new generation total 9216K, used 4178K [0x029d0000, 0x033d0000, 0x033d0000)
eden space 8192K, 51% used [0x029d0000, 0x02de4828, 0x031d0000)
from space 1024K, 0% used [0x031d0000, 0x031d0000, 0x032d0000)
to space 1024K, 0% used [0x032d0000, 0x032d0000, 0x033d0000)
tenured generation total 10240K, used 4500K [0x033d0000, 0x03dd0000, 0x03dd0000)
the space 10240K, 43% used [0x033d0000, 0x03835348, 0x03835400, 0x03dd0000)
compacting perm gen total 12288K, used 2114K [0x03dd0000, 0x049d0000, 0x07dd0000)
the space 12288K, 17% used [0x03dd0000, 0x03fe0998, 0x03fe0a00, 0x049d0000)
No shared spaces configured.
��MaxTenuringThreshold=15���������еĽ����
[GC [DefNew
Desired Survivor size 524288 bytes, new threshold 15 (max 15)
- age 1: 414664 bytes, 414664 total
: 4859K->404K(9216K), 0.0049637 secs] 4859K->4500K(19456K), 0.0049932 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew
Desired Survivor size 524288 bytes, new threshold 15 (max 15)
- age 2: 414520 bytes, 414520 total
: 4500K->404K(9216K), 0.0008091 secs] 8596K->4500K(19456K), 0.0008305 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap
def new generation total 9216K, used 4582K [0x029d0000, 0x033d0000, 0x033d0000)
eden space 8192K, 51% used [0x029d0000, 0x02de4828, 0x031d0000)
from space 1024K, 39% used [0x031d0000, 0x03235338, 0x032d0000)
to space 1024K, 0% used [0x032d0000, 0x032d0000, 0x033d0000)
tenured generation total 10240K, used 4096K [0x033d0000, 0x03dd0000, 0x03dd0000)
the space 10240K, 40% used [0x033d0000, 0x037d0010, 0x037d0200, 0x03dd0000)
compacting perm gen total 12288K, used 2114K [0x03dd0000, 0x049d0000, 0x07dd0000)
the space 12288K, 17% used [0x03dd0000, 0x03fe0998, 0x03fe0a00, 0x049d0000)
No shared spaces configured.
��̬���������ж�
Ϊ���ܸ��õ���Ӧ��ͬ������ڴ�״�����������������Զ��Ҫ�������������ﵽ��MaxTenuringThreshold���ܽ���������������Survivor�ռ�����ͬ�������ж����С���ܺʹ���Survivor�ռ��һ�룬������ڻ���ڸ�����Ķ���Ϳ���ֱ�ӽ��������������ȵ�MaxTenuringThreshold��Ҫ������䡣
ִ����������е�testTenuringThreshold2()������������-XX:MaxTenuringThreshold=15���ᷢ�����н����Survivor�Ŀռ�ռ����ȻΪ0%�����������Ԥ��������6%��Ҳ����˵��allocation1��allocation2����ֱ�ӽ��������������û�еȵ�15����ٽ����䡣��Ϊ����������������Ѿ�������512KB������������ͬ��ģ�����ͬ�����ﵽSurvivor�ռ��һ���������ֻҪע�͵�����һ������new�������ͻᷢ������һ���Ͳ���������������ȥ�ˡ�
private static final int _1MB = 1024 * 1024;
/**
* VM������-verbose:gc -Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=15
* -XX:+PrintTenuringDistribution
*/
@SuppressWarnings("unused")
public static void testTenuringThreshold2() {
byte[] allocation1, allocation2, allocation3, allocation4;
allocation1 = new byte[_1MB / 4];
// allocation1+allocation2����survivo�ռ�һ��
allocation2 = new byte[_1MB / 4];
allocation3 = new byte[4 * _1MB];
allocation4 = new byte[4 * _1MB];
allocation4 = null;
allocation4 = new byte[4 * _1MB];
}
������
[GC [DefNew
Desired Survivor size 524288 bytes, new threshold 1 (max 15)
- age 1: 676824 bytes, 676824 total
: 5115K->660K(9216K), 0.0050136 secs] 5115K->4756K(19456K), 0.0050443 secs] [Times: user=0.00 sys=0.01, real=0.01 secs]
[GC [DefNew
Desired Survivor size 524288 bytes, new threshold 15 (max 15)
: 4756K->0K(9216K), 0.0010571 secs] 8852K->4756K(19456K), 0.0011009 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap
def new generation total 9216K, used 4178K [0x029d0000, 0x033d0000, 0x033d0000)
eden space 8192K, 51% used [0x029d0000, 0x02de4828, 0x031d0000)
from space 1024K, 0% used [0x031d0000, 0x031d0000, 0x032d0000)
to space 1024K, 0% used [0x032d0000, 0x032d0000, 0x033d0000)
tenured generation total 10240K, used 4756K [0x033d0000, 0x03dd0000, 0x03dd0000)
the space 10240K, 46% used [0x033d0000, 0x038753e8, 0x03875400, 0x03dd0000)
compacting perm gen total 12288K, used 2114K [0x03dd0000, 0x049d0000, 0x07dd0000)
the space 12288K, 17% used [0x03dd0000, 0x03fe09a0, 0x03fe0a00, 0x049d0000)
No shared spaces configured.
�ռ���䵣��
�ڷ���Minor GC֮ǰ����������ȼ������������õ������ռ��Ƿ�������������ж����ܿռ䣬������������������ôMinor GC����ȷ���ǰ�ȫ�ġ���������������������鿴HandlePromotionFailure����ֵ�Ƿ���������ʧ�ܡ������������ô������������������õ������ռ��Ƿ�������ν���������������ƽ����С��������ڣ��������Ž���һ��Minor GC���������Minor GC���з��յģ����С�ڣ�����HandlePromotionFailure���ò�����ð�գ�����ʱҲҪ��Ϊ����һ��Full GC��
�������һ�¡�ð�ա���ð��ʲô���գ�ǰ���ᵽ����������ʹ�ø����ռ��㷨����Ϊ���ڴ������ʣ�ֻʹ������һ��Survivor�ռ�����Ϊ�ֻ����ݣ���˵����ִ���������Minor GC����Ȼ�����������˵���������ڴ���պ������������ж���������Ҫ��������з��䵣������Survivor�����ɵĶ���ֱ�ӽ�����������������еĴ�������ƣ������Ҫ���������ĵ�����ǰ�����������������������Щ�����ʣ��ռ䣬һ���ж��ٶ�����������ʵ������ڴ����֮ǰ������ȷ֪���ģ�����ֻ��ȡ֮ǰÿһ�λ��ս��������������������ƽ����Сֵ��Ϊ����ֵ�����������ʣ��ռ���бȽϣ������Ƿ����Full GC����������ڳ�����ռ䡣
ȡƽ��ֵ���бȽ���ʵ��Ȼ��һ�ֶ�̬���ʵ��ֶΣ�Ҳ����˵�����ij��Minor GC����Ķ���ͻ����ԶԶ����ƽ��ֵ�Ļ�����Ȼ�ᵼ�µ���ʧ�ܣ�Handle Promotion Failure�������������HandlePromotionFailureʧ�ܣ��Ǿ�ֻ����ʧ�ܺ����·���һ��Full GC����Ȼ����ʧ��ʱ�Ƶ�Ȧ�������ģ���������¶����ǻὫHandlePromotionFailure���ش�����Full GC����Ƶ�����μ�������룬����JDK 6 Update 24֮ǰ�İ汾�����в��ԡ�
private static final int _1MB = 1024 * 1024;
/**
* VM������-Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8 -XX:-HandlePromotionFailure
*/
@SuppressWarnings("unused")
public static void testHandlePromotion() {
byte[] allocation1, allocation2, allocation3, allocation4, allocation5, allocation6, allocation7;
allocation1 = new byte[2 * _1MB];
allocation2 = new byte[2 * _1MB];
allocation3 = new byte[2 * _1MB];
allocation1 = null;
allocation4 = new byte[2 * _1MB];
allocation5 = new byte[2 * _1MB];
allocation6 = new byte[2 * _1MB];
allocation4 = null;
allocation5 = null;
allocation6 = null;
allocation7 = new byte[2 * _1MB];
}
��HandlePromotionFailure = false���������еĽ����
[GC [DefNew: 6651K->148K(9216K), 0.0078936 secs] 6651K->4244K(19456K), 0.0079192 secs] [Times: user=0.00 sys=0.02, real=0.02 secs]
[GC [DefNew: 6378K->6378K(9216K), 0.0000206 secs][Tenured: 4096K->4244K(10240K), 0.0042901 secs] 10474K->4244K(19456K), [Perm : 2104K->2104K(12288K)], 0.0043613 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
��HandlePromotionFailure = true���������еĽ����
[GC [DefNew: 6651K->148K(9216K), 0.0054913 secs] 6651K->4244K(19456K), 0.0055327 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 6378K->148K(9216K), 0.0006584 secs] 10474K->4244K(19456K), 0.0006857 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
��JDK 6 Update 24֮��������Խ�����в��죬HandlePromotionFailure����������Ӱ�쵽������Ŀռ���䵣�����ԣ��۲�OpenJDK�е�Դ��仯����������룩����ȻԴ���л�������HandlePromotionFailure�����������ڴ������Ѿ�������ʹ������JDK 6 Update 24֮��Ĺ����ΪֻҪ������������ռ���������������ܴ�С�������ν�����ƽ����С�ͻ����Minor GC��������Full GC��
bool TenuredGeneration::promotion_attempt_is_safe(size_t
max_promotion_in_bytes) const{
// ����������õ������ռ�
size_t available = max_contiguous_available();
// ÿ�ν������������ƽ����С
size_t av_promo = (size_t) gc_stats()->avg_promoted()->padded_average();
// ��������ÿռ��Ƿ����ƽ��������С��������������ÿռ��Ƿ���ڵ���GCʱ���������ж�������
bool res = (available >= av_promo) || (available >=
max_promotion_in_bytes);
return res;
}
��ǩ��
��Ȩ��������վ���²��������磬������Ȩ������ϵ��west999com@outlook.com
�ر�ע�⣺��վ����ת���������۲�������վ�۵㣬��վ���ṩ����Ӱ��Ƭ���廭�������Ʒ������ʹ�ã�����ԭ������ϵ����Ȩ��ԭ��������

��һƪ����Ϣ����֮ ActiveMQ
��һƪ��Java�ڴ�����Ļ��ֺ��쳣
- �������Ա������Java��Դ��ȫ��ȫ���Ǹɻ��� 2020-06-12
- 2020�������й�ƽ��������Java�м���������ϼ������𰸣� 2020-06-11
- 2020��java��ҵǰ�� 2020-06-11
- 04.Java����� 2020-06-11
- Java--����(�����Ƶ����)���� 2020-06-11
IDC��Ѷ�� ������Ѷ ע����Ѷ �й���Ѷ vps��Ѷ ��վ����
��վ��Ӫ�� ��վ���� ��ӯ�� �����Ż� ��վ�ƹ� �����Դ
��վ���ˣ� �������� ���˽��� ���˵��� ������
��ҵ��Ѷ�� �������� ������Ϸ �������� ��洫ý
�����̣� Asp.Net��� Asp��� Php��� Xml��� Access Mssql Mysql ����
������������ Web������ Ftp������ Mail������ Dns������ ��ȫ����
�������ɣ� �������� Word Excel Powerpoint Ghost Vista QQ�ռ� QQ FlashGet Ѹ��
��ҳ������ FrontPages Dreamweaver Javascript css photoshop fireworks Flash
������ƣ� Java���� C/C++ VB delphi

- ʲô�������Ե�ȡ�ź�����,��ô����
- ����������վ����2020�����
- springcloudѧϰ֮·: (һ) ��Ĵ�
- ����Gradle���̳���Could not install
- ����Ū����PKIX path building failed
- Tomcat��������:org.apache.catalina.L
- spring boot ����Check your ViewRes
- ����HttpClient���°���������ϵͳģ��
- ֻ�г���Ա���ܿ����ij��ƣ�������Ȼ��
- mybatis ע��@Results��@Result��@Resu