
JAVA―集合框架
2018-06-18 01:25:19来源:未知 阅读 ()

ref:https://blog.csdn.net/u012961566/article/details/76915755
https://blog.csdn.net/u011240877/article/details/52773577
https://blog.csdn.net/wangguidong520/article/details/53516570
https://www.cnblogs.com/leeplogs/p/5891861.html
集合框架(collections framework)
首先要明确,集合代表了一组对象(和数组一样,但数组长度不能变,而集合能)。Java中的集合框架定义了一套规范,用来表示、操作集合,使具体操作与实现细节解耦。
集合框架是一个用来代表和操纵集合的统一架构。所有的集合框架都包含如下内容:
- 接口:是代表集合的抽象数据类型。接口允许集合独立操纵其代表的细节。在面向对象的语言,接口通常形成一个层次。
- 实现(类):是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构。
- 算法:是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。这些算法被称为多态,那是因为相同的方法可以在相似的接口上有着不同的实现。
两大基类Collection与Map
在集合框架的类继承体系中,最顶层有两个接口:
Collection表示一组纯数据;Map表示一组key-value对。
Java 集合框架主要结构图

---|Collection: 单列集合
---|List: 有存储顺序, 可重复
---|ArrayList: 数组实现, 查找快, 增删慢
由于是数组实现, 在增和删的时候会牵扯到数组增容, 以及拷贝元素. 所以慢。数组是可以直接按索引查找, 所以查找时较快
---|LinkedList: 链表实现, 增删快, 查找慢
由于链表实现, 增加时只要让前一个元素记住自己就可以, 删除时让前一个元素记住后一个元素, 后一个元素记住前一个元素. 这样的增删效率较高但查询时需要一个一个的遍历, 所以效率较低
---|Vector: 和ArrayList原理相同, 但线程安全, 效率略低
和ArrayList实现方式相同, 但考虑了线程安全问题, 所以效率略低
---|Set: 无存储顺序, 不可重复
---|HashSet
---|TreeSet
---|LinkedHashSet
---|Map: 键值对
---|HashMap
---|TreeMap
---|HashTable
---|LinkedHashMap
一、Collection接口
Collection接口定义了一个包含一批对象的集合。接口的主要方法包括:
- size() - 集合内的对象数量;
- add(E)/addAll(Collection) - 向集合内添加单个/批量对象;
- remove(Object)/removeAll(Collection) - 从集合内删除单个/批量对象;
- contains(Object)/containsAll(Collection) - 判断集合中是否存在某个/某些对象;
- toArray() - 返回包含集合内所有对象的数组等。
二、Map接口
Map接口在Collection的基础上,为其中的每个对象指定了一个key,并使用Entry保存每个key-value对,以实现通过key快速定位到对象(value)。Map接口的主要方法包括:
- size() - 集合内的对象数量
- put(K,V)/putAll(Map) - 向Map内添加单个/批量对象
- get(K) - 返回Key对应的对象
- remove(K) - 删除Key对应的对象
- keySet() - 返回包含Map中所有key的Set
- values() - 返回包含Map中所有value的Collection
- entrySet() - 返回包含Map中所有key-value对的EntrySet
- containsKey(K)/containsValue(V) - 判断Map中是否存在指定key/value等。
1.1 Collection接口继承树

1.2 Collection接口是Set、List和Queue接口的父接口,基本操作包括:
- add(Object o):增加元素
- contains(Object o):是否包含指定元素
- containsAll(Collection c):是否包含集合c中的所有元素
- iterator():返回Iterator对象,用于遍历集合中的元素
- remove(Object o):移除元素
- removeAll(Collection c):相当于减集合c
- retainAll(Collection c):相当于求与c的交集
- size():返回元素个数
- toArray():把集合转换为一个数组
1.3 Collection的遍历可以使用Iterator接口或者是foreach循环来实现
参考:Java:集合,数组(Array)、集合(List/Set/Queue)、映射(Map)等的迭代遍历,比如:ArrayList,LinkedList,HashSet,HashMap
1.4 Set子接口
Set集合不允许包含相同的元素,而判断两个对象是否相同则是根据equals方法。
1.4.1 HashSet类
HashSet类是Set接口的典型实现类。特点:
- 不能保证元素的排列顺序,加入的元素要特别注意hashCode()方法的实现。
- HashSet不是同步的,多线程访问同一步HashSet对象时,需要手工同步。
- 集合元素值可以是null。
1.4.2 LinkedHashSet类
LinkedHashSet类也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序。与HashSet相比,特点:
- 对集合迭代时,按增加顺序返回元素。
- 性能略低于HashSet,因为需要维护元素的插入顺序。但迭代访问元素时会有好性能,因为它采用链表维护内部顺序。
1.4.3 SortedSet接口及TreeSet实现类
TreeSet类是SortedSet接口的实现类。因为需要排序,所以性能肯定差于HashSet。与HashSet相比,额外增加的方法有:
- first():返回第一个元素
- last():返回最后一个元素
- lower(Object o):返回指定元素之前的元素
- higher(Obect o):返回指定元素之后的元素
- subSet(fromElement, toElement):返回子集合
可以定义比较器(Comparator)来实现自定义的排序。默认自然升序排序。
1.4.4 EnumSet类
EnumSet类是专为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值。《Effective Java》第32条,用EnumSet代替位域,示范:

// EnumSet - a modern replacement for bit fields - Page 160
import java.util.*;
public class Text {
public enum Style { BOLD, ITALIC, UNDERLINE, STRIKETHROUGH }
// Any Set could be passed in, but EnumSet is clearly best
public void applyStyles(Set<Style> styles) {
// Body goes here
}
// Sample use
public static void main(String[] args) {
Text text = new Text();
text.applyStyles(EnumSet.of(Style.BOLD, Style.ITALIC));
}
}
1.5 List子接口
List子接口是有序集合,所以与Set相比,增加了与索引位置相关的操作:
- add(int index, Object o):在指定位置插入元素
- addAll(int index, Collection c):...
- get(int index):取得指定位置元素
- indexOf(Obejct o):返回对象o在集合中第一次出现的位置
- lastIndexOf(Object o):...
- remove(int index):删除并返回指定位置的元素
- set(int index, Object o):替换指定位置元素
- subList(int fromIndex, int endIndex):返回子集合
1.5.1 ArrayList和Vector实现类
- 这两个类都是基于数组实现的List类。
- ArrayList是线程不安全的,而Vector是线程安全的。但Vector的性能会比ArrayList低,且考虑到兼容性的原因,有很多重复方法。
- Vector提供一个子类Stack,可以挺方便的模拟“栈”这种数据结构(LIFO,后进先出)。
结论:不推荐使用Vector类,即使需要考虑同步,即也可以通过其它方法实现。同样我们也可以通过ArrayDeque类或LinkedList类实现“栈”的相关功能。所以Vector与子类Stack,建议放进历史吧。
1.5.2 LinkedList类
不像ArrayList是基于数组实现的线性表,LinkedList类是基于链表实现的。
另外还有固定长度的List:Arrays工具类的方法asList(Object... a)可以将数组转换为List集合,它是Arrays内部类ArrayList的实例,特点是不可以增加元素,也不可以删除元素。
1.6 Queue子接口
Queue用于模拟队列这种数据结构,实现“FIFO”等数据结构。通常,队列不允许随机访问队列中的元素。
Queue 接口并未定义阻塞队列的方法,而这在并发编程中是很常见的。BlockingQueue 接口定义了那些等待元素出现或等待队列中有可用空间的方法,这些方法扩展了此接口。
Queue 实现通常不允许插入 null 元素,尽管某些实现(如 LinkedList)并不禁止插入 null。即使在允许 null 的实现中,也不应该将 null 插入到 Queue 中,因为 null 也用作 poll 方法的一个特殊返回值,表明队列不包含元素。
基本操作:
- boolean add(E e) : 将元素加入到队尾,不建议使用
- boolean offer(E e): 将指定的元素插入此队列(如果立即可行且不会违反容量限制),当使用有容量限制的队列时,此方法通常要优于 add(E),后者可能无法插入元素,而只是抛出一个异常。推荐使用此方法取代add
- E remove(): 获取头部元素并且删除元素,不建议使用
- E poll(): 获取头部元素并且删除元素,队列为空返回null;推荐使用此方法取代remove
- E element(): 获取但是不移除此队列的头
- E peek(): 获取队列头部元素却不删除元素,队列为空返回null
@Test
public void testQueue() {
Queue<String> queue = new LinkedList<String>();
queue.offer("1.你在哪儿?");
queue.offer("2.我在这里。");
queue.offer("3.那你又在哪儿呢?");
String str = null;
while ((str = queue.poll()) != null) {
System.out.println(str);
}
}
1.6.1 PriorityQueue类
PriorityQueue保存队列元素的顺序并不是按照加入队列的顺序,而是按队列元素的大小重新排序。当调用peek()或者是poll()方法时,返回的是队列中最小的元素。当然你可以与TreeSet一样,可以自定义排序。自定义排序的一个示范:
@Test
public void testPriorityQueue() {
PriorityQueue<Integer> pq = new PriorityQueue<Integer>(20, new Comparator<Integer>() {
public int compare(Integer i, Integer j) {
// 对数字进行奇偶分类,然后比较返回;偶数有较低的返回值(对2取余数然后相减),奇数直接相减。
int result = i % 2 - j % 2;
if (result == 0)
result = i - j;
return result;
}
});
// 倒序插入测试数据
for (int i = 0; i < 20; i++) {
pq.offer(20 - i);
}
// 打印结果,偶数因为有较低的值,所以排在前面
for (int i = 0; i < 20; i++) {
System.out.println(pq.poll());
}
}
输出:
2,4,6,8,10,12,14,16,18,20,1,3,5,7,9,11,13,15,17,19,
1.6.2 Deque子接口与ArrayDeque类
Deque代表一个双端队列,可以当作一个双端队列使用,也可以当作“栈”来使用,因为它包含出栈pop()与入栈push()方法。
ArrayDeque类为Deque的实现类,数组方式实现。方法有:
- addFirst(Object o):元素增加至队列开头
- addLast(Object o):元素增加至队列末尾
- poolFirst():获取并删除队列第一个元素,队列为空返回null
- poolLast():获取并删除队列最后一个元素,队列为空返回null
- pop():“栈”方法,出栈,相当于removeFirst()
- push(Object o):“栈”方法,入栈,相当于addFirst()
- removeFirst():获取并删除队列第一个元素
- removeLast():获取并删除队列最后一个元素
1.6.3 实现List接口与Deque接口的LinkedList类
LinkedList类是List接口的实现类,同时它也实现了Deque接口。因此它也可以当做一个双端队列来用,也可以当作“栈”来使用。并且,它是以链表的形式来实现的,这样的结果是它的随机访问集合中的元素时性能较差,但插入与删除操作性能非常出色。
1.7 各种线性表选择策略
- 数组:是以一段连续内存保存数据的;随机访问是最快的,但不支持插入、删除、迭代等操作。
- ArrayList与ArrayDeque:以数组实现;随机访问速度还行,插入、删除、迭代操作速度一般;线程不安全。
- Vector:以数组实现;随机访问速度一般,插入、删除、迭代速度不太好;线程安全的。
- LinkedList:以链表实现;随机访问速度不太好,插入、删除、迭代速度非常快。
2.1 Map接口继承树

2.2 Map集合方法概要
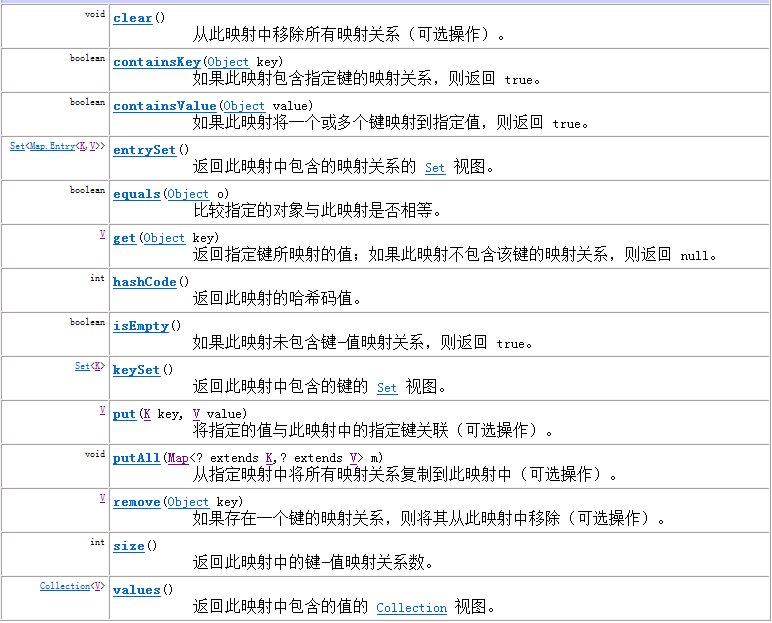
2.3 Map接口
---| Map 接口 将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
---|Hashtable:
底层是哈希表数据结构,线程是同步的,不可以存入null键,null值。Hashtable与HashMap类似,是HashMap的线程安全版,它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢,它继承自Dictionary类,不同的是它不允许记录的键或者值为null,同时效率较低。效率较低,被HashMap 替代。
---|HashMap:
底层是哈希表数据结构,线程是不同步的,可以存入null键,null值。HashMap是最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。因为键对象不可以重复,所以HashMap最多只允许一条记录的键为Null,允许多条记录的值为Null,是非同步的。要保证键的唯一性,需要覆盖hashCode方法,和equals方法。
---| LinkedHashMap:
该子类基于哈希表又融入了链表。可以Map集合进行增删提高效率。 LinkedHashMap保存了记录的插入顺序,在用Iteraor遍历LinkedHashMap时,先得到的记录肯定是先插入的,在遍历的时候会比HashMap慢,有HashMap的全部特性。
---|TreeMap:
底层是二叉树数据结构。可以对map集合中的键进行排序。需要使用Comparable或者Comparator 进行比较排序。return 0,来判断键的唯一性。TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序(自然顺序),也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。不允许key值为空,非同步的;
---|ConcurrentHashMap
线程安全,并且锁分离。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hashtable,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
三、主要实现类区别小结
Vector和ArrayList
- vector是线程同步的,所以它也是线程安全的,而arraylist是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用arraylist效率比较高。
- 如果集合中的元素的数目大于目前集合数组的长度时,vector增长率为目前数组长度的100%,而arraylist增长率为目前数组长度的50%。如果在集合中使用数据量比较大的数据,用vector有一定的优势。
- 如果查找一个指定位置的数据,vector和arraylist使用的时间是相同的,如果频繁的访问数据,这个时候使用vector和arraylist都可以。而如果移动一个指定位置会导致后面的元素都发生移动,这个时候就应该考虑到使用linklist,因为它移动一个指定位置的数据时其它元素不移动。
ArrayList 和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,都允许直接序号索引元素,但是插入数据要涉及到数组元素移动等内存操作,所以索引数据快,插入数据慢,Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差,LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快。
arraylist和linkedlist
- ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
- 对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
- 对于新增和删除操作add和remove,LinkedList比较占优势,因为ArrayList要移动数据。 这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
HashMap与TreeMap
- HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。
- 在Map 中插入、删除和定位元素,HashMap是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。使用HashMap要求添加的键类明确定义了hashCode()和 equals()的实现。
两个map中的元素一样,但顺序不一样,导致hashCode()不一样。
同样做测试:
在HashMap中,同样的值的map,顺序不同,equals时,false;
而在treeMap中,同样的值的map,顺序不同,equals时,true,说明,treeMap在equals()时是整理了顺序了的。
HashTable与HashMap
- 同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的。
- HashMap允许存在一个为null的key,多个为null的value 。
- hashtable的key和value都不允许为null。
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

下一篇:Spring消息之STOMP
- 国外程序员整理的Java资源大全(全部是干货) 2020-06-12
- 2020年深圳中国平安各部门Java中级面试真题合集(附答案) 2020-06-11
- 2020年java就业前景 2020-06-11
- 04.Java基础语法 2020-06-11
- Java--反射(框架设计的灵魂)案例 2020-06-11
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
