
Java --本地提交MapReduce作业至集群?实现 Word …
2018-07-04 02:07:23来源:博客园 阅读 ()

还是那句话,看别人写的的总是觉得心累,代码一贴,一打包,扔到Hadoop上跑一遍就完事了????写个测试样例程序(MapReduce中的Hello World)还要这么麻烦!!!?,还本地打Jar包,传到Linux上,最后再用jar命令运行jar包敲一遍in和out参数,我去,我是受不了了,我很捉急, 。
。
我就想知道MapReduce的工作原理,而知道原理后,我就想在本地用Java程序跑一遍整个MapReduce的计算过程,这个很难吗? 搜遍全网,没发现几个是自己想要的(也有可能漏掉了),都是可以参考的,但是零零散散不对胃口,不适合入门级“玩家”像我一样的人,最后,下定决心,看视频搜集资料,从头到尾的捋一下MapReduce的原理,以及如何在本地,通过编写map和reduce函数对一个文本文件中的单词进行出现次数的统计,并将结果输出到HDFS文件系统上
注: 本文最后,还会附上一套自己写的HDFS的文件操作Java API,使用起来也很方便,API还在不断的完善..
效果:
1、 HelloWorld文本
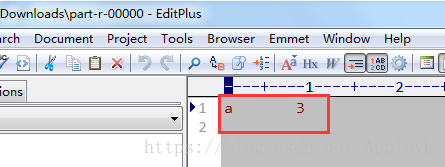
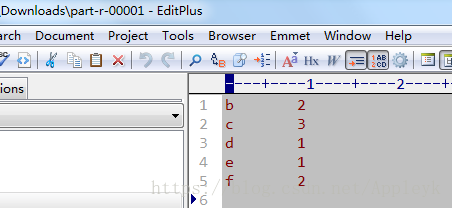
a b c d e f a c a c b f

2、上传至HDFS的intput目录下
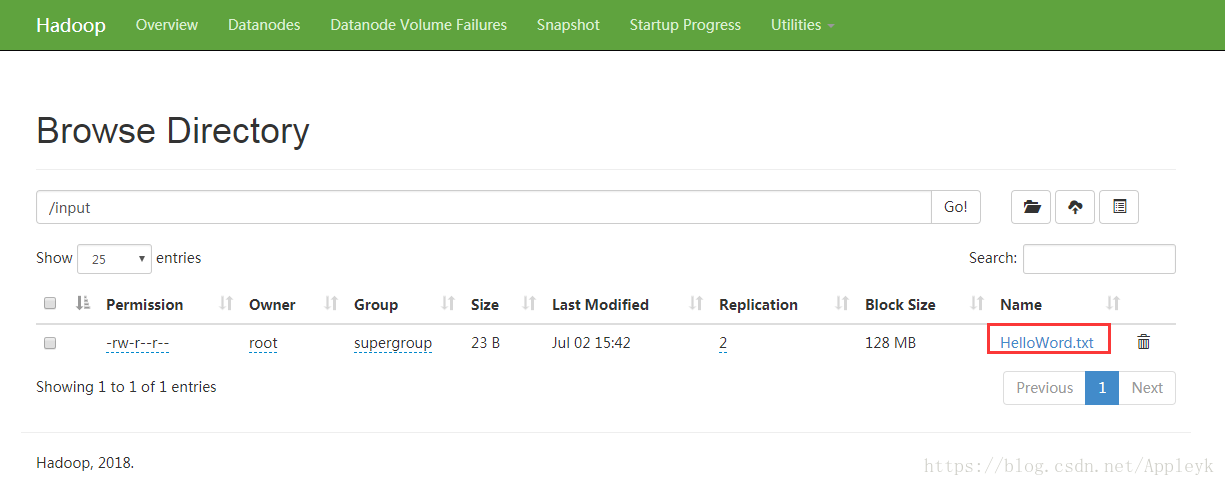
3、客户端提交Job,执行MapReduce
A、map的输出结果
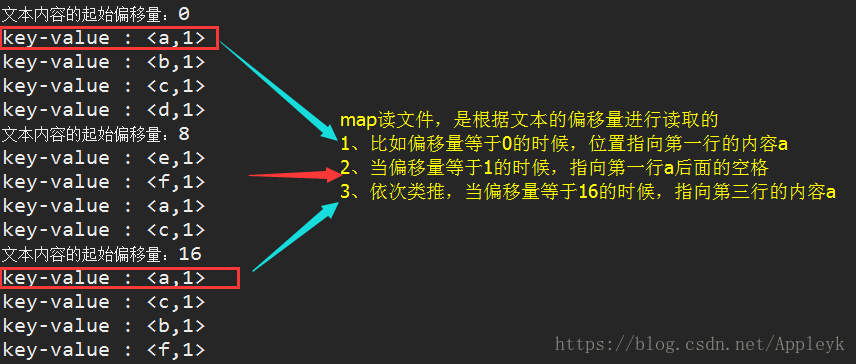
B、reduce的输入结果(上一步map的输出)

C、reduce的计算结果(代码实现细节先暂时忽略,文章中会讲到)

D、最后,待任务全部完成,交由HDFS进行结果的文件写入


MapReduce中的分区默认是哈希分区,但是我们也可以自己写demo来重写Partitioner类的getPartiton方法,如下:
分区规则定后,我们需要指定客户端Job的map task的分区类并设置reducer的个数,如下

最后,提交Job跑一遍MapReduce的效果如下:
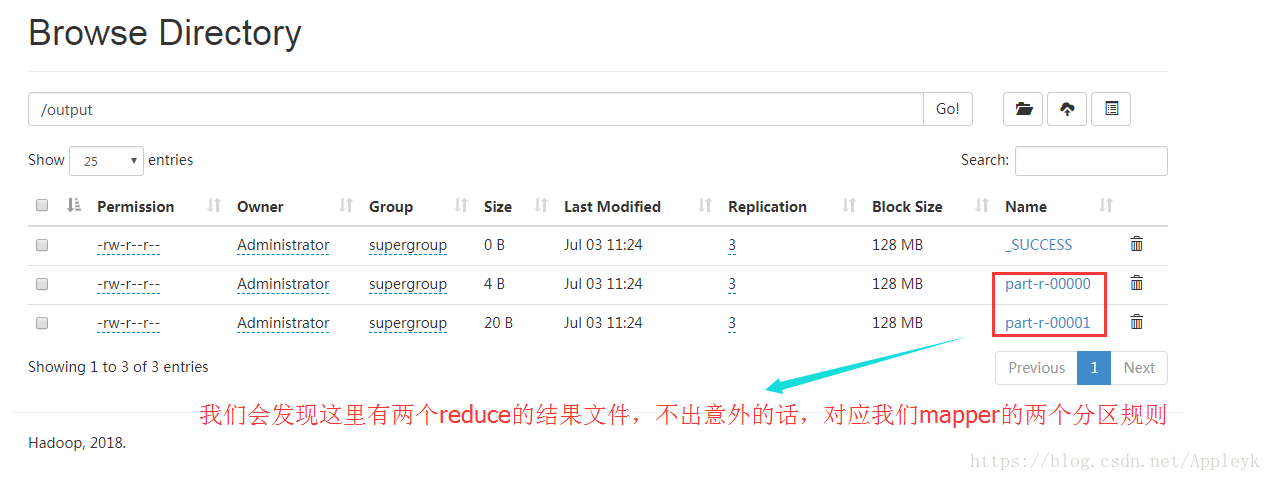
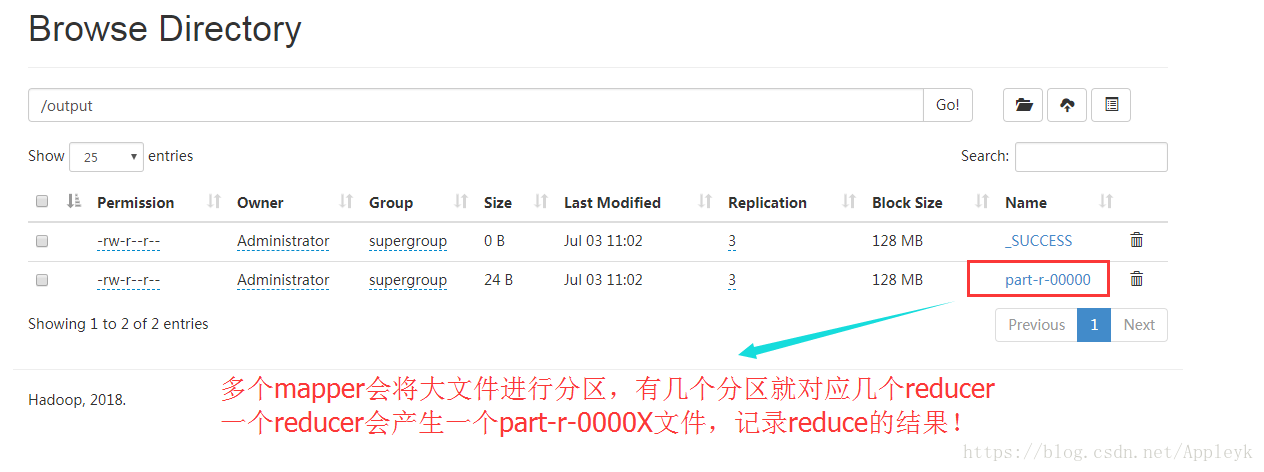
我们分别下载文件*.*-00000和*.*-00001至本地,并进行结果验证,效果如下:
分区0对应的reduce结果文件如下:
分区1对应的reduce结果文件如下:
至此,我用效果图的方式,给大家演示了一下MapReduce的前前后后究竟是如何进行map和reduce的,其中发生了什么,最后又发生了什么,很直观,但是,注意,效果图只能帮助你理解MapReduce最终能干什么,具体MapReduce内部的工作原理如何,我下面会继续讲到,而且,博文的末尾,我会附上本篇博文演示要用到的全demo。
一、什么是MapReduce
我们要数图书馆里面的所有书,你数1号书架,我数2号书架,他数3号书架...这就叫Map
现在我们把所有人统计的图书数加在(归并)一起,这就叫“Reduce”
合起来就是MapReduce【分布式大数据处理功能】!!!
详细的请查看:MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算
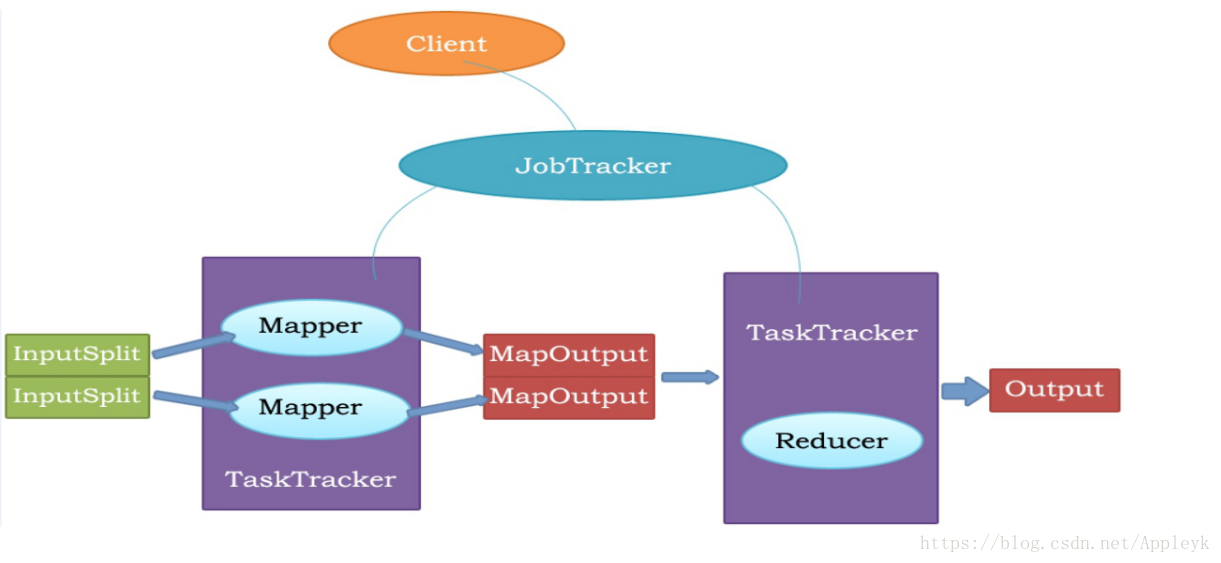
二、MapReduce执行过程
补充:
1、JobTracker 对应于 NameNode,TaskTracker 对应于 DataNode。
2、JobTracker是一个master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。一般情况应该把JobTracker部署在单独的机器上。
Client :客户端提交一个Job给JobTracker
JobTracker :调度Job的每一个mapper和reducer,并运行在TaskTracker上,并监控它们
Mapper :拿到符合自己的InputSplit(输入内容),进行map后,输出MapOutPut(map的输出内容)
Reducer : 拿到MapOutPut作为自己的ReduceInput,进行reduce计算,最后输出OutPut结果
三、MapReduce工作原理
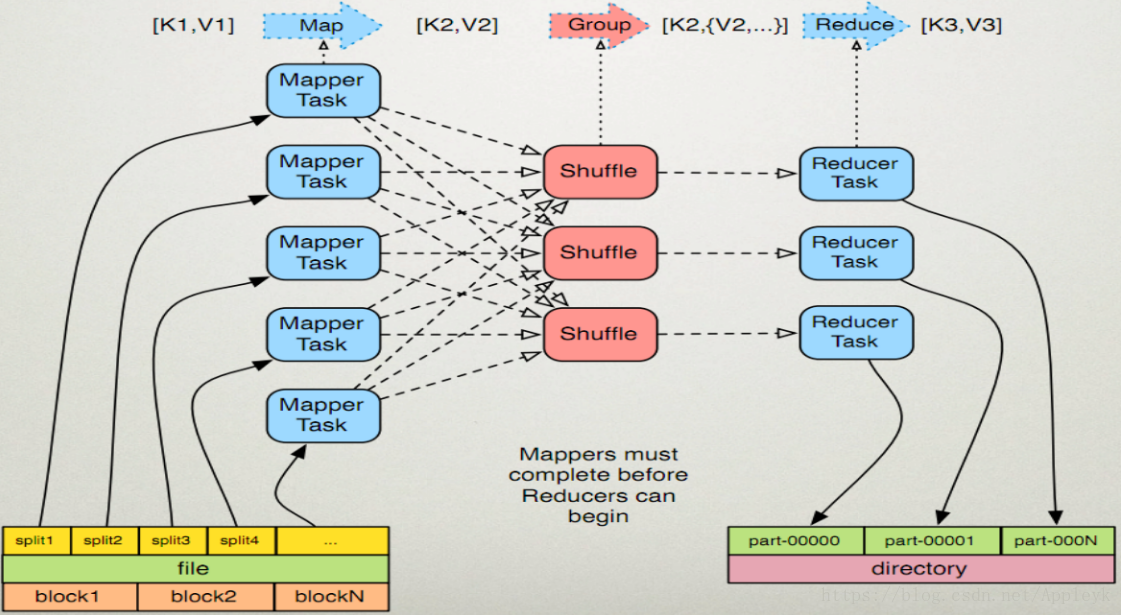
注:reducer开始reduce之前,一定要等待mapper完成map后才能开始
第一步:Job读取存在于 HDFS文件系统上的文件作为Mapper的输入内容(key,value)并经过特殊的处理(map编程实现)交由Mapper Task
第二步:Mapper Task对map后的数据进行shuffle(洗牌,重组),包括分区、排序或合并(combine)
第三步:Mapper把shuffle后的输出结果(key,values)提供给对应的Reducer Task,由Reducer取走
第四步:Reducer拿到上一步Mapper的输出结果,进行reduce(客户端编程实现)
第五步:Reducer完成reduce计算后,将结果写入HDFS文件系统,不同的reducer对应不同的结果文件
粗犷的图(自己画的)如下

四、Shuffle过程简介

上图需要注意的就是shuffle过程中的分区,图中很直观的说明了,mapper最后会把key-value键值对数据(输入数据)从缓存中拿出(缓存数据溢出)并根据分区规则进行磁盘文件的写入(注意:这里的磁盘文件不是HDFS文件系统上的文件,且写入文件的内容已经是排序过的了),同时会对不同分区的key-value数据文件进行一个归并,最后分给不同的Reduce任务进行reduce处理,如果有多个Mapper,则Reducer从Map端获取的内容需要再次进行归并(把属于不同的Mapper但属于同一个分区的输出的结果进行归并,并在reduce端也进行shuffle过程,写入磁盘文件,最后进行reduce计算,reduce计算的结果最后以文件的形式输出到HDFS文件系统中)
五、Map端的Shuffle过程
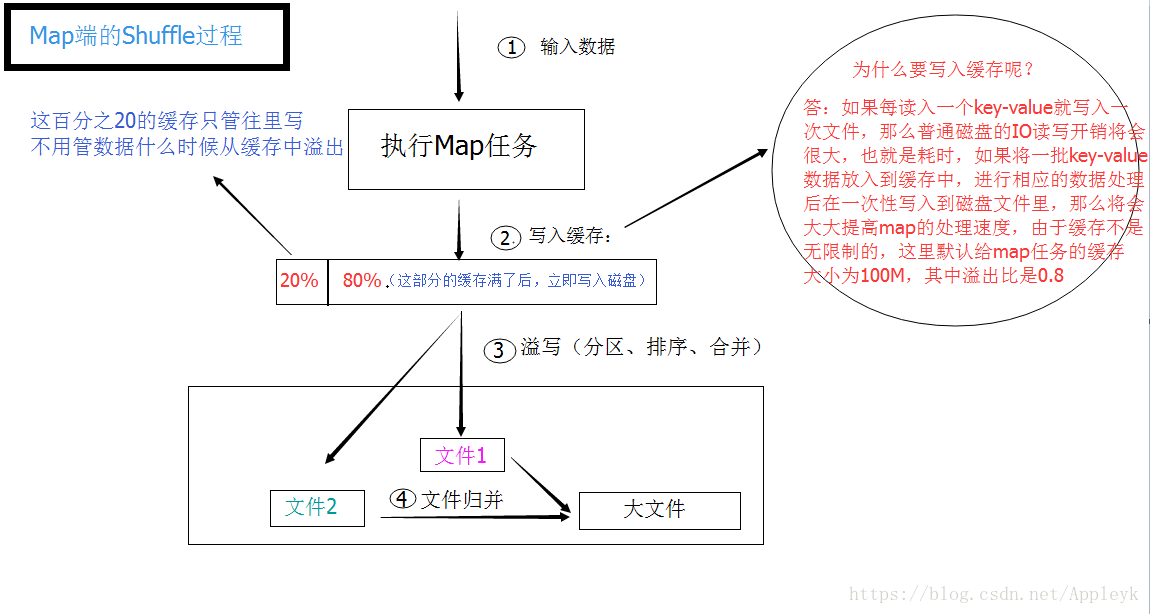
需要知道的是:
1、缓存的大小是可以设置的(mapreduce.task.io.sort.mb,默认100M)
2、溢出比(缓存使用率有一个软阈值 == mapreduce.map.sort.spill.percent,默认0.80),当超过阈值时,溢出行为会在后台起一个线程执行从而使Map任务不会因为缓存的溢出而被阻塞。但如果达到硬限制,Map任务会被阻塞,直到溢出行为结束
六、如何编写map和reduce函数
到这一步,如果你对MapReduce的工作原理已经掌握了,那么接下来,编写客户端程序,利用MapReduce的计算功能,实现文本文件中单词的出现次数的统计,将会是轻而易举的。
首先,我们需要一个mapper(任务),其次是reducer(任务),有了两个任务后,我们需要创建一个Job(作业),将mapper和reducer关联起来,并提交至Hadoop集群,由集群中的JobTracker进行mapper和reducer任务的调度,并最终完成数据的计算工作。
因此,不难发现,光有mapper和reducer任务,是无法进行MapReduce(分布式大数据计算)的,这里我们需要写三个类,一个是实现Map的类,一个是实现Reduce的类,还有一个就是提交作业的主类(Client Main Class)
由于博主的Hadoop版本是3.1.0的,因此,为了兼顾3.X以下的Hadoop集群环境能够在下面提供的demo中能够跑起来,特将本文中涉及到的Hadoop依赖换成了2.7.X的版本,如下:
注意:不要使用过时的hadoop-core(1.2.1)依赖,否则会出现各种意想不到的的问题
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.1</version> </dependency> <!-- common 依赖 tools.jar包 --> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.8</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency>
(1)编写Mapper

import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * Mapper 原型 : Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> * * KEYIN : 默认情况下,是mr框架所读到的一行文本内容的起始偏移量,Long, * 但是在hadoop中有自己的更精简的序列化接口,所以不直接用Long,而用LongWritable * VALUEIN : 默认情况下,是mr框架所读到的一行文本的内容(Java String 对应 Hadoop中的Text) * KEYOUT : 用户自定义逻辑处理完成之后输出数据中的key,在此处是单词(String),同上用Text * VALUEOUT : 用户自定义逻辑处理完成之后输出数据中的value,在这里是单词的次数:Integer,对应Hadoop中的IntWritable * * mapper的输入输出参数的类型必须和reducer的一致,且mapper的输出是reducer的输入 * * @blob http://blog.csdn.net/appleyk * @date 2018年7月3日15:41:13 */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ /** * map实现数据拆分的操作 * 本操作主要进行Map的数据处理 * 在Mapper父类里面接受的内容如下: * LongWritable:文本内容的起始偏移量 * Text:每行的文本数据(行内容) * Text:每个单词分解后的统计结果 * IntWritable:输出记录的结果 */ @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { System.out.println("文本内容的起始偏移量:"+key); String line = value.toString() ;//取出每行的数据 String[] result = line.split(" ");//按照空格进行数据拆分 //循环单词 for (int i = 0 ;i <result.length ; i++){ //针对每一个单词,构造一个key-value System.out.println("key-value : <"+new Text(result[i])+","+new IntWritable(1)+">"); /** * 将每个单词的key-value写入到输入输出上下文对象中 * 并传递给mapper进行shuffle过程,待所有mapper task完成后交由reducer进行对号取走 */ context.write(new Text(result[i]), new IntWritable(1)); } /** map端的shuffle过程(大致简单的描述一下) * | * | 放缓存(默认100M,溢出比是0.8,即80M满进行磁盘写入并清空, * | 剩余20M继续写入缓存,二者结合完美实现边写缓存边溢写(写磁盘)) * V * <b,1>,<c,1>,<a,1>,<a,1> * * | * | 缓存写满了,开始shuffle(洗牌、重组) == 包括分区,排序,以及可进行自定的合并(combine) * V * 写入磁盘文件(not hdfs)并进行文件归并,成一个个的大文件 <a,<1,1>>,<b,1>,<c,1> * * | * | * V * 每一个大文件都有各自的分区,有几个分区就对应几个reducer,随后文件被各自的reducer领走 * * !!! 这就是所谓的mapper的输入即是reducer的输出 !!! */ } }
(2)编写Reducer
import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /** * 进行合并后数据的最终统计 * 本次要使用的类型信息如下: * Text:Map输出的文本内容 * IntWritable:Map处理的个数 * Text:Reduce输出文本 * IntWritable:Reduce的输出个数 */ public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { //mapper的输出是reducer的输入,因此,这里打一下reducer的接收内容 List<Integer> list = new ArrayList<>(); int sum = 0;//记录每个单词(key)出现的次数 for (IntWritable value : values) { //从values集合里面取出key的单个频率数量(其实就是1)进行叠加 int num = value.get(); sum += num; list.add(num); } /** * mapper会把一堆key-value进行shuffle操作,其中涉及分区、排序以及合并(combine) * 注:上述shuffle中的的合并(combine)区别于map最终的的合(归)并(merge) * 比如有三个键值对:<a,1>,<b,1>,<a,1> * combine的结果:<a,2>,<b,1> == 被reducer取走,数据小 * merage 的结果;<a,<1,1>>,<b,1> == 被reducer取走,数据较大(相比较上述combine来说) * 注:默认combiner是需要用户自定义进行开启的,所以,最终mapper的输出其实是归并(merage)后的的结果 * * 所以,下面的打印其实就是想看一下mapper在shuffle这个过程后的merage结果(一堆key-values) */ System.out.println("key-values :<"+key+","+list.toString().replace("[", "<") .replace("]", ">")+">"); //打印一下reduce的结果 System.out.println("reduce计算结果 == key-value :<"+key+","+new IntWritable(sum)+">"); //最后写入到输入输出上下文对象里面,传递给reducer进行shuffle,待所有reducer task完成后交由HDFS进行文件写入 context.write(key, new IntWritable(sum)); } }
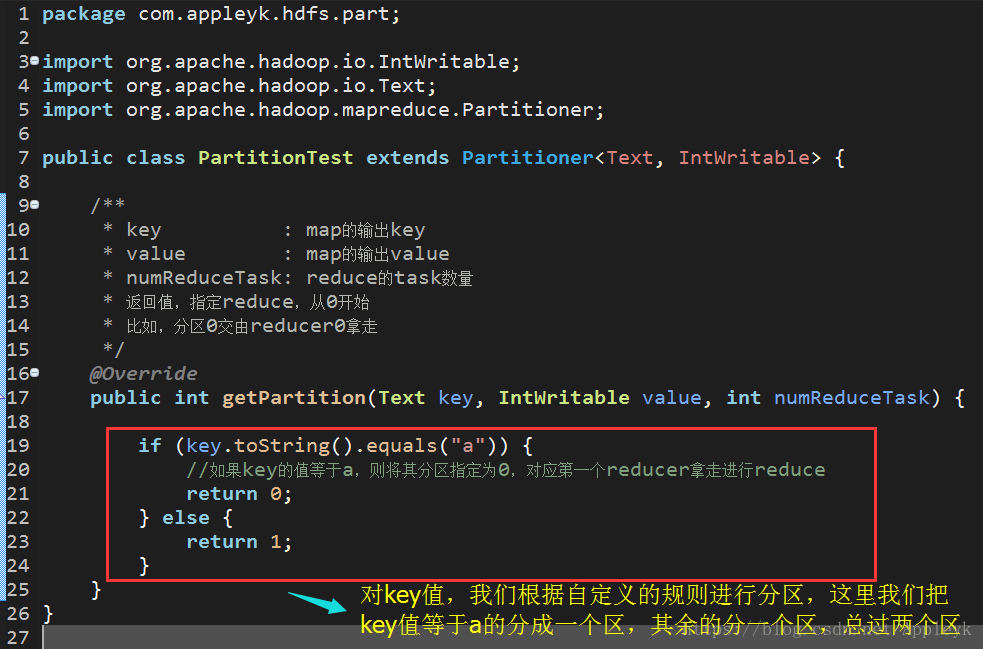
(3)编写Partition分区类(如果需要修改Map默认的哈希分区规则的话)
1 import org.apache.hadoop.io.IntWritable; 2 import org.apache.hadoop.io.Text; 3 import org.apache.hadoop.mapreduce.Partitioner; 4 5 public class PartitionTest extends Partitioner<Text, IntWritable> { 6 7 /** 8 * key : map的输出key 9 * value : map的输出value 10 * numReduceTask: reduce的task数量 11 * 返回值,指定reduce,从0开始 12 * 比如,分区0交由reducer0拿走 13 */ 14 @Override 15 public int getPartition(Text key, IntWritable value, int numReduceTask) { 16 17 if (key.toString().equals("a")) { 18 //如果key的值等于a,则将其分区指定为0,对应第一个reducer拿走进行reduce 19 return 0; 20 } else { 21 return 1; 22 } 23 } 24 }
(4)编写Job类(Main Class)

1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.fs.Path; 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Job; 6 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 7 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 8 9 import com.appleyk.hdfs.mapper.WordCountMapper; 10 import com.appleyk.hdfs.part.PartitionTest; 11 import com.appleyk.hdfs.reducer.WordCountReducer; 12 13 /** 14 * Client端,提交作业 15 * @author yukun24@126.com 16 * @blob http://blog.csdn.net/appleyk 17 * @date 2018年7月3日-上午9:51:49 18 */ 19 public class WordCountApp { 20 21 public static void main(String[] args) throws Exception{ 22 23 Configuration conf = new Configuration(); 24 //配置uri 25 conf.set("fs.defaultFS", "hdfs://192.168.142.138:9000"); 26 27 //创建一个作业,作业名"wordCount",作用在Hadoop集群上(remote) 28 Job job = Job.getInstance(conf, "wordCount"); 29 30 /** 31 * 设置jar包的主类(如果样例demo打成Jar包扔在Linux下跑任务, 32 * 需要指定jar包的Main Class,也就是指定jar包运行的主入口main函数) 33 */ 34 job.setJarByClass(WordCountApp.class); 35 36 //设置Mapper 任务的类(自己写demo实现map) 37 job.setMapperClass(WordCountMapper.class); 38 //设置Reducer任务的类(自己写demo实现reduce) 39 job.setReducerClass(WordCountReducer.class); 40 41 //指定mapper的分区类 42 //job.setPartitionerClass(PartitionTest.class); 43 44 //设置reducer(reduce task)的数量(从0开始) 45 //job.setNumReduceTasks(2); 46 47 48 //设置映射输出数据的键(key) 类(型) 49 job.setMapOutputKeyClass(Text.class); 50 //设置映射输出数据的值(value)类(型) 51 job.setMapOutputValueClass(IntWritable.class); 52 53 //设置作业(Job)输出数据的键(key) 类(型) == 最后要写入到输出文件里面 54 job.setOutputKeyClass(Text.class); 55 //设置作业(Job)输出数据的值(value)类(型) == 最后要写入到输出文件里面 56 job.setOutputValueClass(IntWritable.class); 57 58 //设置输入的Path列表(可以是单个文件也可以是多个文件(目录表示即可)) 59 FileInputFormat.setInputPaths (job, new Path("hdfs://192.168.142.138:9000/input" )); 60 //设置输出的目录Path(确认输出Path不存在,如存在,请先进行目录删除) 61 FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.142.138:9000/output")); 62 63 //将作业提交到集群并等待它完成。 64 boolean bb =job.waitForCompletion(true); 65 66 if (!bb) { 67 System.out.println("Job作业执行失败!"); 68 } else { 69 System.out.println("Job作业执行成功!"); 70 } 71 } 72 73 }
(5)运行main方法,提交作业
出现异常:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z

将源代码全部拷贝出来,在项目下新建一个同包名同类名称的文件如下:

打开后,修改代码如下(去掉验证):

(6)再次运行main方法,提交作业
再次出现异常:
org.apache.hadoop.security.AccessControlException:
Permission denied: user=Administrator, access=WRITE,inode="/":root:supergroup:drwxr-xr-x
意思是再说,我当前使用的user是Windows下的Administrator,但是在Hadoop的HDFS文件系统中,没有这个用户,因此,我想用Administrator这个用户向HDFS文件系统Write的时候出现权限不足的异常,因为HDFS文件系统根目录下的文件对其他用户来说,不具备w和r的权限
原本把mapreduce程序打包放在集群中跑是不用担心用户的hdfs权限问题的,但是,我一开始说了,我不想那么麻烦,无非就是Hadoop开启了HDFS文件系统的权限验证功能,我给它关了(开放)不就行了,因此,我决定直接在hdfs-site.xml配置文件里进行权限验证的修改,添加内容如下:
<property> <name>dfs.permissions</name> <value>false</value> </property>
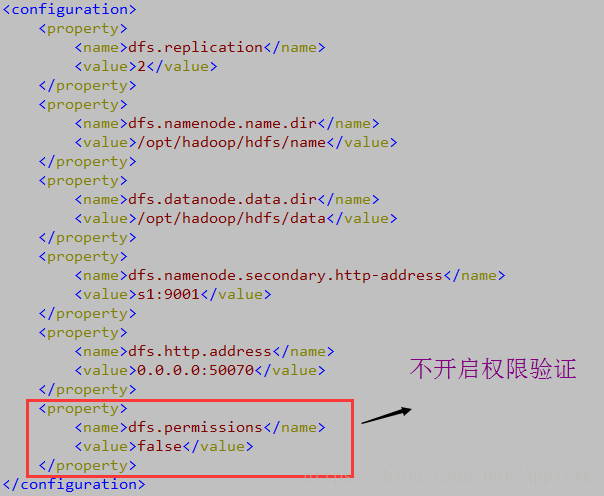
保存后,重启Hadoop集群
先stop,再start

(7)再次运行main方法,提交作业
16:55:44.385 [main] INFO org.apache.hadoop.mapreduce.Job - map 100% reduce 100% 16:55:44.385 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.getTaskCompletionEvents(Job.java:670) 16:55:44.385 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:320) 16:55:44.386 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:320) 16:55:44.386 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.getTaskCompletionEvents(Job.java:670) 16:55:44.386 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:320) 16:55:44.386 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:320) 16:55:44.387 [main] INFO org.apache.hadoop.mapreduce.Job - Job job_local539916280_0001 completed successfully 16:55:44.388 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.getCounters(Job.java:758) 16:55:44.407 [main] INFO org.apache.hadoop.mapreduce.Job - Counters: 35 File System Counters FILE: Number of bytes read=560 FILE: Number of bytes written=573902 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=46 HDFS: Number of bytes written=24 HDFS: Number of read operations=13 HDFS: Number of large read operations=0 HDFS: Number of write operations=4 Map-Reduce Framework Map input records=3 Map output records=12 Map output bytes=72 Map output materialized bytes=102 Input split bytes=112 Combine input records=0 Combine output records=0 Reduce input groups=6 Reduce shuffle bytes=102 Reduce input records=12 Reduce output records=6 Spilled Records=24 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=3 Total committed heap usage (bytes)=605028352 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=23 File Output Format Counters Bytes Written=24 16:55:44.407 [main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:320) Job作业执行成功!
ok,至此,本地执行mapreduce作业已经完成,接下来就是查看我们要的结果了
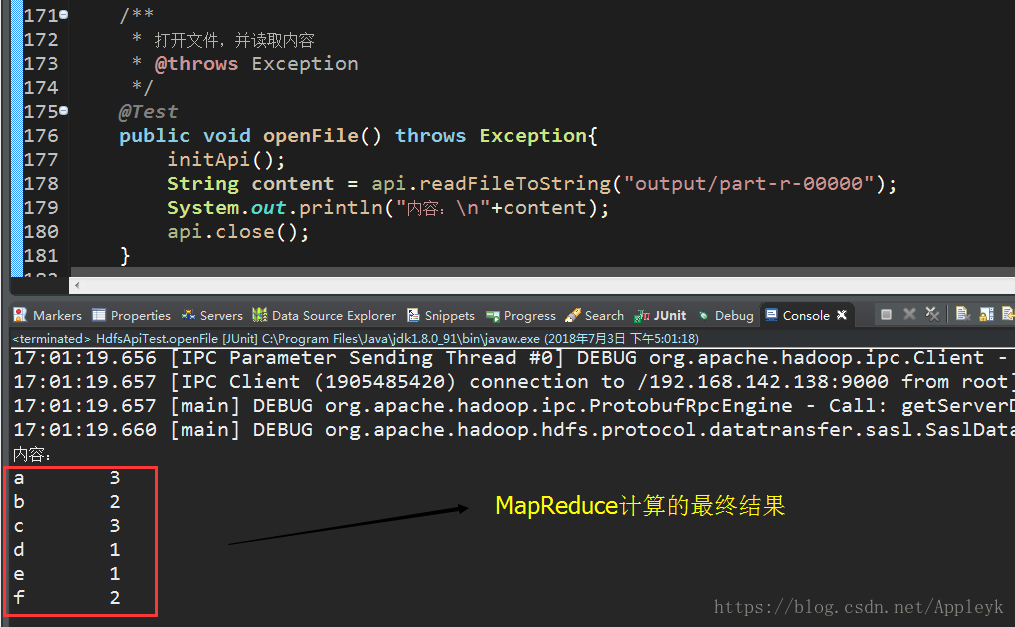
(8)利用Java HDFS API,打开/output/part-r-00000文件内容,输出到控制台

a b c d e f a c a c b f
七、GitHub项目地址
Java HDFS API ,实现文件的存储和访问 并附带MapReduce作业,本地提交作业至集群实现Word Count的计算
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

上一篇:Vim和Vi的常用命令
- MPI 本地局域网运行多机配置,同时运行多个程序; 2020-06-02
- 由java程序引起的一次系统崩溃 2020-05-27
- Javaweb项目配置到阿里云服务器 2020-05-06
- 针对Linux上Java程式运行脚本的Log信息记录操作人员记录以及 2020-04-27
- 假设本地源yum 2020-04-19
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
